从日志中提取用户代理
我有大型日志文件,其中包含用户代理的字段。现在这个字段的位置可能因日志而异,我试图提取完整的用户代理字符串。 到目前为止,我尝试过的正则表达式选项并不适用于我在这些日志中获得的所有用户代理。他们似乎对大多数人都有用。
以下是我在日志中获得的一些示例用户代理
" field1的" " FIELD2" " Mozilla / 5.0(Macintosh; Intel Mac OS X 10_7_0)AppleWebKit / 535.11(KHTML,如Gecko)Chrome / 17.0.963.65 Safari / 535.11"
" field1的" " Sundance(兼容; Windows; U; en-US;)版本/ 0.9.0.38" " FIELD2" "字段3"
" yacybot(i386 Linux 2.6.24-24-generic; java 1.6.0_07; Europe / en)http://yacy.net/bot.html" " field1的" " FIELD2"
" field1的" " FIELD2" " Lynx / 2.8.5rel.1 libwww-FM / 2.14 SSL-MM / 1.4.1 OpenSSL / 0.9.7m"
我使用的正则表达式(不适用于所有正则表)如下所示
([^/\s]*)(/([^\s]*))?(\s*\[[a-zA-Z][a-zA-Z]\])?\s*(\((([^()]|(\([^()]*\)))*)\))?\s*
原始日志是用引号括起来的空格分隔字段(类似于squid日志),因此我可以确定每个日志行中用户代理字符串的开头和结尾。但是每个日志文件中字段的位置都不同。
如果我能在改进这种正则表达式模式方面得到一些帮助,那将是最好的。我需要的是正则表达式能够匹配我列出的所有上述用户代理字符串。
任何帮助都将受到高度赞赏。
修改
我想要实现的是我需要从不同的日志文件中提取包含用户代理字符串的字段。日志文件包含一系列空格分隔并用引号括起来的字段。
1 个答案:
答案 0 :(得分:4)
回答这个问题的关键在于确定所有用户代理字符串之间的共性,这些字符串不能存在于任何其他字段中。问题是说起来容易做起来难,特别是因为它的格式只有惯例 - 而不是硬性和快速的规则。然而,存在真实用户代理字符串的列表,例如, here和here。
以下示例 - 选择您喜欢的选项或混合搭配:
-
在引号中查找至少一个空格 - 用户代理(最简单,但显然不适用于第一个用户代理字符串,即
"Mosaic/0.9") :"[^"]* [^"]*" -
查找至少一个版本号(两位数用小数点分隔 - 仅当保证不在任何其他字段中时) - 第一个捕获组中的用户代理:
"([^"]*\d\.\d[^"]*)" -
寻找更复杂的东西(可能是你最好的选择,如果以上工作都没有,你有一个有限的已知用户代理列表,搜索文本可以在任何一个其他字段) - 使用前瞻的不带引号的用户代理:
[^"]*(mozilla|opera|ipad|applewebkit|khtml|7b405|bot|sundance|lynx|etc|etc)[^"]*(?=")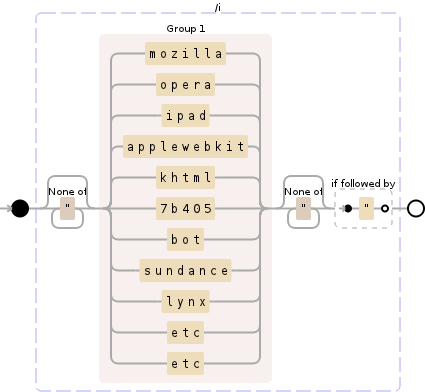
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?