使用正则表达式以多种方式匹配相同的字符串
我有以下代码:
import re
pattern = re.compile('^(.+)\'s (.+)$',re.I)
string = "bill's uncle's pony"
matchObjects = pattern.finditer(string)
for i in matchObjects:
if i:
print i.group(1)
print i.group(2)
这会产生输出:
bill's uncle
pony
当我希望它会产生输出
bill's uncle
pony
bill
uncle's pony
也就是说,我想要字符串匹配的所有方式。这段代码只给了我一个。任何想法都非常赞赏。
2 个答案:
答案 0 :(得分:1)
"也就是说,我想要字符串匹配的所有方式。这段代码只给我一个。"
那不是真的。它为您提供了仅使用 方式的正则表达式与您的输入匹配。这是greedy +量词所做的事情:它跳过除最后一个之外的所有可能性 - 只要仍然可以进行匹配。
因此,您永远不会只使用当前的正则表达式uncle's。
也许你可以做两次,首先是当前贪婪的正则表达式
^(.+)\'s (.+)$
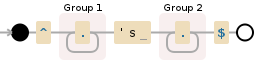
然后再次使用reluctant版本:
^(.+?)\'s (.+)$
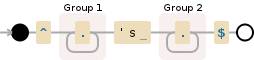
贪婪匹配bill's uncle和pony。不情愿的匹配bill和uncle's pony。
但是"找到所有匹配的概念"没有意义。正则表达式以完全一种方式匹配或不匹配输入字符串。
(我对debuggex图像完全相同感到惊讶。)
请考虑将Stack Overflow Regular Expressions FAQ加入书签以供将来参考。
答案 1 :(得分:-1)
之前建议DOTALL,但这并不好。尝试使用非贪婪修饰符“?”
pattern = re.compile('^(.+?)\'s (.+?)$',re.I)
仍然没有给予exactley所需的输出,但也许它会帮助我们走上正轨。
输出:
bill
uncle's pony
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?