从python中的随机字符串中提取多个连续数字
我正在尝试将包含ID值的字符串列表解析为一系列7位数,但我不知道如何处理此问题。
lst1=[
"(Tower 3rd fl floor_WINDOW CORNER : option 2_ floor cut out_small_wood) : GA -
Floors : : Model Lines : id 3925810
(Tower 3rd fl floor_WINDOW CORNER : option 2_ floor cut out_small_wood) : GA - Floors : Floors : Floor : Duke new core floors : id 3925721",
"(Tower 3rd fl floor_WINDOW CORNER : option 3_ floor cut out_large_wood) : GA - Floors : : Model Lines : id 3976019
(Tower 3rd fl floor_WINDOW CORNER : option 3_ floor cut out_large_wood) : GA - Floors : Floors : Floor : Duke new core floors : id 3975995"
]
我真的想拉出数字值并将它们组合成一个用冒号“;”分隔的字符串。 结果列表将是这样的:
lst1 = ["3925810; 3925721", "3976019; 3975995"]
2 个答案:
答案 0 :(得分:3)
您可以使用正则表达式,例如
import re
pattern = re.compile(r"\bid\s*?(\d+)")
print ["; ".join(pattern.findall(item)) for item in lst1]
# ['3925810; 3925721', '3976019; 3975995']

如果你想确保你选择的数字长度只有7,那你就可以这样做
pattern = re.compile(r"\bid\s*?(\d{7})\D*?")
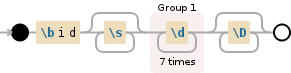
\b指的是单词边界。因此,它确保id将是一个单独的单词,后面跟着0个或更多的空格字符。然后我们匹配数字[0-9],\d只是一个简写符号。 {7}仅匹配七次,后跟\D,后者与\d相反。
答案 1 :(得分:0)
假设您的列表是:
lst1=[
"(Tower 3rd fl floor_WINDOW CORNER : option 2_ floor cut out_small_wood) : GA - Floors : : Model Lines : id 3925810",
"(Tower 3rd fl floor_WINDOW CORNER : option 2_ floor cut out_small_wood) : GA - Floors : Floors : Floor : Duke new core floors : id 3925721",
"(Tower 3rd fl floor_WINDOW CORNER : option 3_ floor cut out_large_wood) : GA - Floors : : Model Lines : id 3976019",
"(Tower 3rd fl floor_WINDOW CORNER : option 3_ floor cut out_large_wood) : GA - Floors : Floors : Floor : Duke new core floors : id 3975995"
]
这样可以解决问题:
lst2 = [i.rsplit(" ",1)[1] for i in lst1]
给出:
['3925810', '3925721', '3976019', '3975995']
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?