如何python正则表达式匹配以下?
1<assume tab here>Algebra I<assume tab here>START
1.1 What are the Basic Numbers? 1-1
对于上面两行中的每一行,我如何正则表达式只匹配&#34;?&#34;的数字。从本质上讲,我想要以下几组:
["1", "Algebra I"]
["1.1", "What are the Basic Numbers?"]
匹配所有内容,包括问号,或最多为&#34;标签字符&#34;。 我怎么能用一个正则表达式做到这一点?
2 个答案:
答案 0 :(得分:5)
这是一个简单的正则表达式:
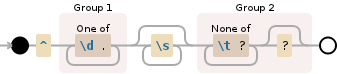
^([\d.]+)\s*([^\t?]+\??)
第1组是数字,第2组包含文本。
要检索一个匹配项:
match = re.search(r"^([\d.]+)\s*([^\t?]+\??)", s)
if match:
mynumbers = match.group(1)
myline = match.group(2)
要迭代匹配,请从以下位置获取第1组和第2组:
reobj = re.compile(r"^([\d.]+)\s*([^\t?]+\??)", re.MULTILINE)
for match in reobj.finditer(s):
# matched text: match.group()
答案 1 :(得分:0)
你走了:
(\d(?:\.\d)*)\s+(?:(.*?\?|.*?)\t)
有关说明:(\d(?:\.\d)*)匹配一个后跟零个或多个.\d的数字。接下来是一个或多个空白字符,后跟任何({懒惰而不是贪婪)(.*?),后面跟着?或\ t在非捕获组中。
输出:
string1 = "1.1 What are the Basic Numbers? 1-1"
string2 = '1\tAlgebra I\tSTART'
m = re.match(pattern, string2)
m.group(1)
#'1'
m.group(2)
#'Algebra I'
m = re.match(pattern, string1)
m.group(1)
#'1.1'
m.group(2)
#'What are the Basic Numbers?'
编辑:添加了非捕获组。
编辑#2:将其修复为包含问号
编辑#3修复了群组。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?