sed只使用正则表达式编辑文件的一部分
我有一个名为test.txt的文件,其中包含以下内容
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<test time="60" id="01">
<java.lang.String value="cat"/><java.lang.String value="dog"/>
<java.lang.String value="mouse"/>
<java.lang.String value="cow"/>
</test>
我想要做的是,我想编辑该文件,以便当我得到类似的内容时,<java.lang.String value="something"/>我会将该部分更改为<animal>something</animal>
因此,对于前面的示例,在使用sed/awk/grep命令应用脚本后,文件内容将更改为或将创建一个新文件,如下所示:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<test time="60" id="01">
<animal>cat</animal><animal>dog</animal>
<animal>mouse</animal>
<animal>cow</animal>
</test>
我尝试使用以下命令提取该特定部分:
$less test.txt | grep -Po 'java.lang.String value="\K[^"]*' | awk -F: '{print "<animal>" $1 "</animal>"}'
输出给了我改变的部分,但是我希望这个改变的部分和文件的其余部分保持不变:
<animal>cat</animal>
<animal>dog</animal>
<animal>mouse</animal>
<animal>cow</animal>
我是脚本新手,我不知道如何在文件中编写完整的输出。
2 个答案:
答案 0 :(得分:4)
sed -r 's#<java.lang.String value="([^"]*)"/>#<animal>\1</animal>#g' test.txt
你不应该用正则表达式进行XML转换......
关于其运作方式的编辑
默认情况下,sed使用&#34;基本正则表达式&#34;,其中许多特殊字符必须以\为前缀。 -r标志切换到&#34;扩展正则表达式&#34;语法不那么麻烦。有关详细信息,请参阅OpenGroup。
默认情况下,sed按原样打印输出,除非命令修改它。替换命令类似于s#search_regexp#replacement#flags。分隔符可以是/,#或,。我选择#,因此它与\中的XML字符不会发生冲突。
然后我们匹配<java.lang.String value="anything_except_quotes"/>之类的内容。我们想要重用的部分有括号,它被称为匹配组。在替换中,我们通过\1引用我们在匹配组中捕获的内容。
g标记使sed替换搜索模式的所有出现,而不仅仅是第一个出现。
答案 1 :(得分:2)
确定你的命令有些问题:
less test.txt | grep -Po 'java.lang.String value="\K[^"]*' | awk -F: '{print "<animal>" $1 "</animal>"}'
首先,less无用,grep可以将文件作为参数:
grep -Po 'java.lang.String value="\K[^"]*' test.txt | awk -F: '{print "<animal>" $1 "</animal>"}'
然后您使用grep选择与字符串匹配的行,所以基本上,您的命令序列明确只保留具有{{1}的行}字符串,取出其他所有内容......更简单的解决方案是使用java.lang...:
sed使用sed的替换语法替换匹配,同时在右侧部分中将括号sed -r 's,<java.lang.String value="([^"]*)"\s*/>,<animal>\1</animal>,g' test.txt
和(中的内容提取为)。 \1部分用于匹配不是[^"]字符的所有内容,"运算符用于匹配0次或更多次匹配。 *将匹配空格\s,0次或更多次。
正则表达式是一个自动机,它使用状态和转换来匹配给定的字符串。这里是正则表达式如何运作的视觉效果:
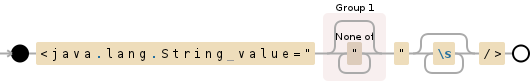
demo of the regex on an example
虽然在您的特定情况下,简单的正则表达式可以解决,但请记住,这只是 hack 。您应该使用XML解析器并使用XSLT / XSLFO替换节点以满足您的需求,这些工具旨在将XML转换为另一个(或其他)。
为此,您可以使用*之类的工具,并查看this Q以获取将所有xsltproc个节点转换为XML树中的foo个节点的示例,这是如何做到的:
test.xsl:
bar运行:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:strip-space elements="*"/>
<!--Identity Template. This will copy everything as-is.-->
<xsl:template match="node()|@*">
<xsl:copy>
<xsl:apply-templates select="node()|@*"/>
</xsl:copy>
</xsl:template>
<!--Change "java.lang.String" element to "animal" element.-->
<xsl:template match="java.lang.String">
<animal>
<!-- get the attribute 'value' of java.lang.String -->
<xsl:copy-of select="@*"/>
<xsl:apply-templates/>
</animal>
</xsl:template>
</xsl:stylesheet>
结果:
xsltproc test.xsl test.xml
顺便说一下,给定你的XML,看起来它是由Java生成的,并且有多种方法可以从within your code应用XSL,甚至在你需要使用命令处理它之前线工具。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?