HyperThreading / SMT是一个有缺陷的概念吗?
HT / SMT背后的主要思想是,当一个线程停止时,同一个核心上的另一个线程可以选择剩余的核心空闲时间并透明地运行它。
2013年,英特尔放弃了SMT,转而支持乱序执行 Silvermont处理器核心,因为他们发现这更好 性能
ARM不再支持SMT(出于能源原因)。 AMD从不支持它。在野外,我们仍然有各种支持它的处理器。
从我的角度来看,如果构建数据和算法是为了不惜一切代价避免缓存未命中和后续处理停滞,那么HT是多核系统中的冗余因素吗?虽然我很欣赏自从两个HyperThreads'以来所涉及的上下文切换开销很低。离散硬件存在于同一物理内核中,我看不出这比没有上下文切换更好。
我建议超线程的任何需要指向有缺陷的软件设计。这里有什么我想念的吗?
5 个答案:
答案 0 :(得分:7)
超线程是否有帮助以及多少取决于线程正在做什么。它不仅仅是在一个线程中工作而另一个线程等待I / O或缓存未命中 - 尽管这是理由的一个重要部分。它是关于有效地使用CPU资源来增加总系统吞吐量。假设你有两个线程
- 一个人有很多数据缓存未命中(空间局部性差)并且不使用浮点,糟糕的空间局部性不一定是因为程序员没有做好工作,一些工作负载本来就是这样。
- 另一个线程是从内存中流式传输数据并进行浮点计算
- 目标市场是什么(运行什么样的应用程序)?
- 目标晶体管技术是什么?
- 什么是表现目标?
- 功率预算是多少?
- 目标芯片尺寸(影响产量)是多少?
- 它适用于公司未来产品的价格/性能范围?
- 目标发布日期是什么时候?
- 有多少资源可用于实施和验证设计?添加微架构功能增加了复杂性,这不是线性的,与其他功能有微妙的交互,目标是在第一个" tapeout"之前识别尽可能多的错误。尽量减少有多少"步入"必须在你有一个工作芯片之前完成。
使用超线程,这两个线程可以共享同一个CPU,一个是进行整数运算并获得缓存未命中和停止,另一个是使用浮点单元,数据预取器远远超前预测来自内存的顺序数据。系统吞吐量优于O / S交替调度同一CPU内核上的两个线程。
英特尔选择不在Silvermont中包含超线程,但这并不意味着它将在高端Xeon服务器处理器中,甚至在针对笔记本电脑的处理器中取消它。为处理器选择微架构涉及权衡,有许多考虑因素:
Silvermont的每个核心和功率预算的芯片尺寸预算不包括无序执行和超线程,并且无序执行提供更好的单线程性能。 Here's Anandtech's assessment:
如果我不得不用Silvermont描述英特尔的设计理念,那将是明智的缩放。我们已经从苹果公司和Swift看到了这一点,从高通公司看到了Krait 200到Krait 300的过渡。请记住使用原始Atom实现的设计规则:每增加2%的性能,Atom架构师最多可以将功率提高1%。换句话说,性能可以提升,但每瓦性能不会下降。 Silvermont坚持这种设计理念,我想我对如何有所了解。
以前版本的Atom使用超线程来充分利用执行资源。超线程有一个与之相关的功率损失,但性能提升足以证明它的合理性。在22nm,英特尔有足够的芯片面积(由于晶体管缩放)只需添加更多内核而不是依赖HT来获得更好的线程性能,因此超线程已经消失。英特尔从摆脱超线程中获得的节能随后被分配用于使Silvermont成为无序设计,这反过来有助于提高执行资源的有效使用而无需HT。事实证明,在22nm处,英特尔用于启用HT的芯片面积与Silvermont的重新订购缓冲器和OoO逻辑大致相同,因此此举甚至没有面积损失。
答案 1 :(得分:4)
无论您的代码在机器上编写和运行的程度如何,CPU处于空闲状态的时间相对较长,而CPU只是在等待某些事情发生。高速缓存未命中是问题的一个子集,等待I / O,用户输入等都可能导致CPU中的冗长停顿,其中仍然可以在第二组寄存器上进行。此外,有几个缓存未命中的原因是您无法计划/周围(例如,在分支上推送新指令,因为您的可执行文件可能并非都适合3级缓存)。
Silvermont离开HT的一个主要原因是,在22纳米处,你有很多(相对)玩耍。因此,您可以使用更多物理内核来提高并行性。
ARM和AMD尚未实施超线程,因为它是英特尔的专有技术。答案 2 :(得分:4)
- 并非所有程序员都有足够的知识,时间和许多其他东西来编写高效,缓存友好的程序。大多数情况下,只有关键部件才会在需要时进行优化。其他部分可能有很多缓存未命中
- 即使编写程序时考虑了缓存效率,也可能无法完全消除缓存未命中。缓存可用性是仅在运行时已知的动态信息,程序员和编译器都不知道优化内存访问。
- 缓存不可预测性为one of the reasons the Itanium failed,因为虽然编译器可以在多线程环境中重新排序算术运算it cannot guess those cache information,但可以有效地重新排序内存加载/存储。
- 每次缓存未命中时,浪费了数百个周期,这对于其他目的非常有用。某些CPU执行无序执行。但即使OoO执行有其限制,你也会在某些时候被阻止。在等待解决所有内存问题的那段时间内,您可以切换到另一个CPU线程并继续运行。
- 现在不只是英特尔使用SMT。 AMD Bulldozer有模块多线程,这是一个部分SMT。还有很多其他架构使用SMT,如MIPS,PowerPC ......甚至有每个内核有8或16个线程的CPU,比如12核96线程power8 CPUs

https://en.wikipedia.org/wiki/Simultaneous_multithreading#Modern_commercial_implementations
更新
AMD现已在Zen microarchitecture 中转向完整的SMT 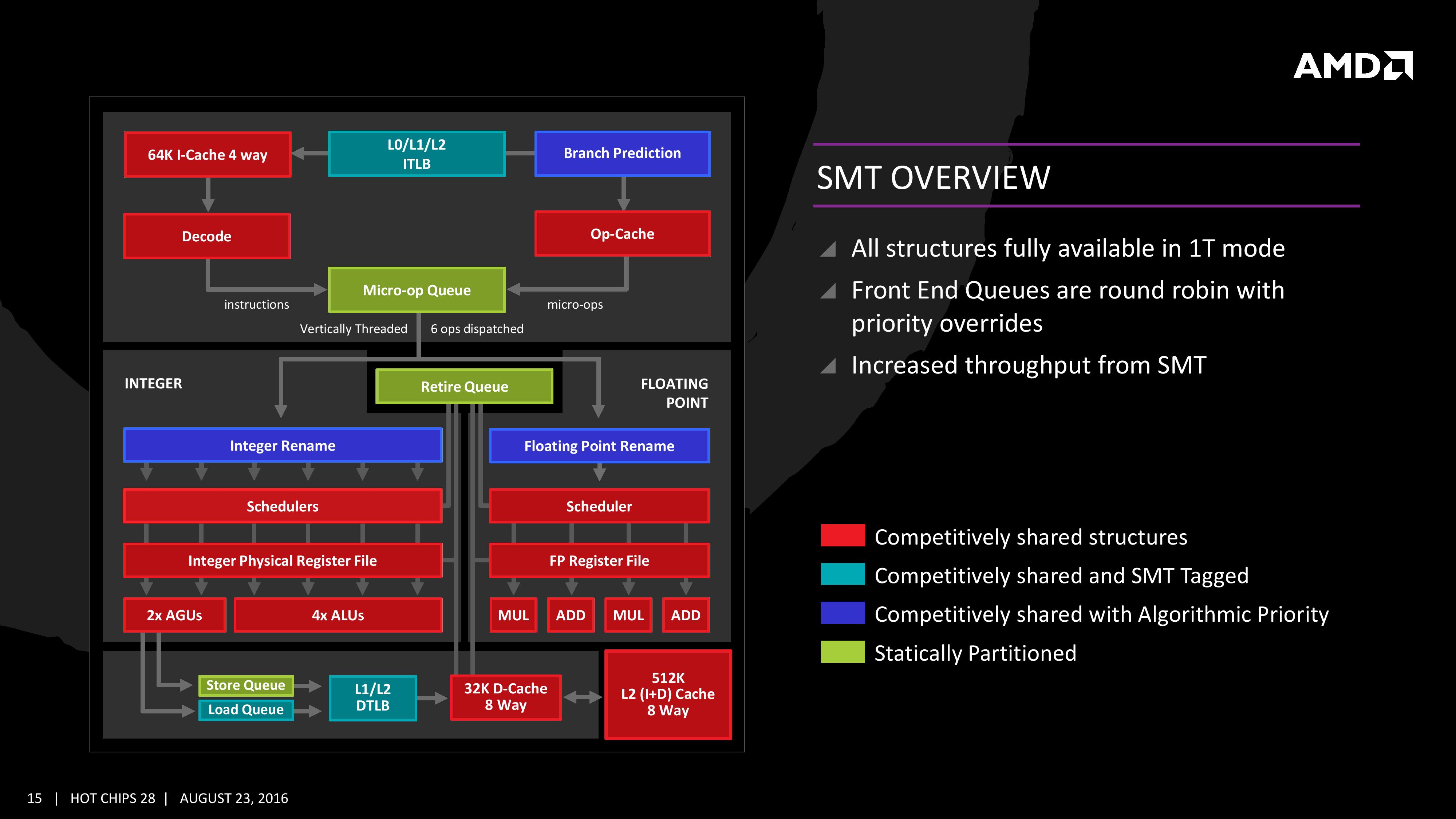
答案 3 :(得分:0)
在使用具有虚拟化功能的8核Atoms之后,我对使用HT的这种芯片的前景垂涎三尺。我同意大多数工作负载可能没有,但是对于ESXi?你会真正令人印象深刻地使用HT。低功耗只是为我打算达成协议。如果您可以在ESXi上获得16个逻辑核心,那么价格/性能将真正达到顶峰。我的意思是,无法承受目前拥有8核和HT的英特尔芯片,而且由于Vsphere和Vsphere产品的使用方式是每个进程许可,双进程主机对于真正的小型企业来说再也没有成本。
答案 4 :(得分:0)
据我所知,作为一名在高吞吐量计算领域的开发人员,SMT/HT 只有一个有用的应用程序,而在所有其他应用程序中,它最多不会让事情变得更糟:
虚拟化 SMT/HT 有助于降低(线程)上下文切换的成本,从而在使用共享相同内核的多个 VM 时大大降低延迟。
但关于吞吐量,我在实践中从未遇到过 SMT/HT 实际上并没有使事情变慢的任何事情。从理论上讲,如果操作系统优化调度进程,它既不会更慢也不会更快,但在实践中,由于 SMT,它碰巧在同一内核上调度了两个要求很高的进程,从而降低了吞吐量。
因此,在所有用于高性能计算的机器上,我们禁用了 HT 和 SMT。在我们所有的测试中,它们都会使计算速度降低约 10-20%。
如果有人有一个真实世界(htoughput 而不是延迟)的例子,其中 smt/HT 实际上没有减慢速度,我会很好奇。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?