如何捕捉多个字母
/**
* SOMETHING BLABLABLA
* Date: 3/16/14
* Time: 8:29 PM
*/
我希望匹配从/ **到* /
的任何内容我可以将/ **与第一个*匹配:
/\*\*([^\*]*)\*
但我不知道如何取消最后两个字母的匹配。
2 个答案:
答案 0 :(得分:3)
您可以使用:
/(?:^\s*\/\*\*)(.*)(?:^\s*\*\/)/ms
或Debuggex版本:
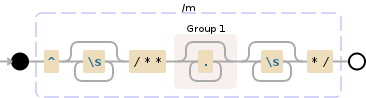
通过' unmatch'我认为你的意思是有一个未包含在比赛组中的组。您使用以(?:regex)开头的非捕获组来执行此操作。
完整的解释是:
/(?:^\s*\/\*\*)(.*)(?:\s*\*\/)/ms
(?:^\s*\/\*\*) Non-capturing group
^ assert position at start of a line
\s* match any white space character [\r\n\t\f ]
Quantifier: Between zero and unlimited times, as many times as possible,
giving back as needed [greedy]
\/ matches the character / literally
\* matches the character * literally
\* matches the character * literally
1st Capturing group (.*)
.* matches any character
Quantifier: Between zero and unlimited times, as many times as possible,
giving back as needed [greedy]
(?:\s*\*\/) Non-capturing group
\s* match any white space character [\r\n\t\f ]
Quantifier: Between zero and unlimited times, as many times as possible, giving back as needed [greedy]
\* matches the character * literally
\/ matches the character / literally
m modifier: multi-line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)
s modifier: single line. Dot matches newline characters
如果你想匹配:
/**
* SOMETHING BLABLABLA
* Date: 3/16/14
* Time: 8:29 PM*/
^ comment terminator
只需将最终非捕获组中的锚点移除为(?:\s*\*\/)
对于Sublime,您需要设置标志ms。使用:
(?ms)(?:^\s*\/\*\*)(.*)(?:^\s*\*\/)
^^^^ This part sets the flags for Boost regex engine...
答案 1 :(得分:2)
试试这个,这需要dot-matches-all:
/\*\*.*?\*/
或者,这会捕获每行上的所有星号后文本......排序:
/\*\*(?:\s+\* ([^\r\n]+))+\s+\*/
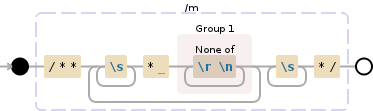
实际上它只捕获最后一行,但看起来确实更接近。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?