正则表达式中的星号
我正在尝试获取冒号后的文本行部分。例如,从这篇文章
previous usc contact name:*assistant director of field education*
agency name:*development corporation
我想得到以下内容:
assistant director of field education
1010 development corporation
我尝试了以下正则表达式
.*:\*?(.*)\**$
它不起作用。现在正在做的是:
.*:\*?(.*)\*
我不明白为什么它在没有星号的第二行工作,正则表达式需要星号。我不明白为什么第一个正则表达式不能正常工作。
感谢。
1 个答案:
答案 0 :(得分:2)
简而言之:
第二个正则表达式.*:\*?(.*)\*有效,因为:
.*匹配:
-
previous usc contact name和 -
agency name
后跟:\*(转义*表示:匹配*)。
(.*)\*最终匹配EVERYHTING直至最后*。
(假设你错过了最后一行的明星,这符合:)
-
assistant director of field education和 -
development corporation
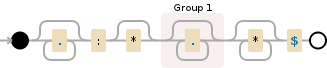
为什么第一个正则表达式失败很难从给出的例子中得知。 .*:\*?(.*)\**$表示,行尾需要为零或多个*(\**)
假设您的换行符是提供的,它只会匹配development corporation,因为锚$(行结束)正常的单行模式,意味着“字符串结束”。因此正则表达式只能匹配ONCE。如果您将修改器更改为多线模式(意味着,$匹配每个\r\n而不仅仅是STR OF STRING)将为您提供所需的结果。
SingleLine-Mode,匹配:
-
development corporation.*:\*?(.*)\**$
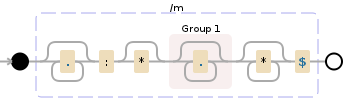
多行模式匹配:
-
assistant director of field education和 -
development corporation.*:\*?(.*)\**$
^和$的beavhiour取决于修饰符:
给出字符串
Hello
World
在单线模式下使用^(.*)$将匹配Hello World。在多行模式下使用相同的模式会在两个不同的匹配组中匹配Hello和World。
在SingleLine中,字符串将由正则表达式引擎处理,如
^Hello
World$
在MultiLine模式下,引擎将其转换为
^Hello$
^World$
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?