混淆Python中正则表达式的用法
我对以下三种模式感到困惑,有人会更详细地解释它吗?
## IPython with Python 2.7.3
In [62]: re.findall(r'[a-z]*',"f233op")
Out[62]: ['f', '', '', '', 'op', ''] ## why does the last '' come out?
In [63]: re.findall(r'([a-z])*',"f233op")
Out[63]: ['f', '', '', '', 'p', ''] ## why does the character 'o' get lost?
In [64]: re.findall(r'([a-z]*)',"f233op")
Out[64]: ['f', '', '', '', 'op', ''] ## what's the different than line 63 above?
4 个答案:
答案 0 :(得分:15)
示例1
re.findall(r'[a-z]*',"f233op")
此模式匹配小写字母字符的零个或多个实例。 ZERO或更多部分在这里是关键,因为从字符串中的每个索引位置开始的任何匹配都与f或op的匹配一样有效。返回的最后一个空字符串是从字符串结尾开始的匹配(p和$之间的位置(字符串结尾)。
示例2
re.findall(r'([a-z])*',"f233op")
现在您要匹配的字符组由一个小写字母字符组成。不再返回o,因为这是一个贪婪的搜索,将返回最后一个有效的匹配组。因此,如果您将字符串更改为f233op12fre,则会返回最终e,但不会返回前面的f或r。同样,如果您在字符串中取出p,仍然会看到o作为有效匹配返回。
相反,如果你试图通过添加?(例如([a-z])*?)来使这个正则表达式非贪婪,那么返回的匹配集将全部为空字符串,因为没有任何有效匹配有效匹配的优先级更高。
示例3
re.findall(r'([a-z]*)',"f233op")
匹配的字符没有什么不同,但现在您返回的是字符组而不是原始匹配。此正则表达式查询的输出将与您的第一个示例相同,但您会注意到,如果添加其他匹配组,您将突然看到每个匹配尝试的结果分组为元组:
IN : re.findall(r'([a-z]*)([0-9]*)',"f233op")
OUT: [('f', '233'), ('op', ''), ('', '')]
将此与相同的模式进行对比,减去括号(组),您将看到它们为什么重要:
IN : re.findall(r'[a-z]*[0-9]*',"f233op")
OUT: ['f233', 'op', '']
另外...
将像这样的正则表达式模式插入正则表图生成器(如Regexplained)以查看模式匹配逻辑的工作方式非常有用。例如,作为您的正则表达式始终返回空字符串匹配的原因的解释,请查看模式[a-z]*和[a-z]+之间的差异。
如果遇到问题,请不要忘记查看Python docs for the re library,它们实际上为标准正则表达式语法提供了一个非常出色的解释。
答案 1 :(得分:6)
-
您获得最终
'',因为[a-z]*与末尾的空字符串匹配。 -
由于您已告知
'o'与群组相匹配,因此缺少字符re.findall,并且每个群组都有一个字符。换句话说,你做的相当于m = re.match(r'([a-z])*', 'op') m.group(1)将返回
'p',因为这是parens捕获的最后一件事(捕获组1)。 -
同样,您正在匹配群组,但这次是多角色群组。
答案 2 :(得分:2)
您惊人的结果与正则表达式量词*有关。
考虑:
[a-z]*
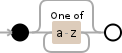
Vs的:
[a-z]+
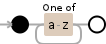
考虑另一个例子,我认为更能说明你所看到的:
>>> re.findall(r'[a-z]*', '123456789')
['', '', '', '', '', '', '', '', '', '']
字符串[a-z]中的集123456789中没有字符。然而,由于*表示'零或更多',所有字符位置'匹配',因为不匹配该位置的任何字符
例如,假设您只想测试字符串中是否有任何字母,并使用正则表达式:
>>> re.search(r'[a-z]*', '1234')
<_sre.SRE_Match object at 0x1069b6988> # a 'match' is returned, but this is
# probably not what was intended
现在考虑:
>>> re.findall(r'[a-z]*', '123abc789')
['', '', '', 'abc', '', '', '', '']
Vs的:
>>> re.findall(r'([a-z])*', '123abc789')
['', '', '', 'c', '', '', '', '']
第一种模式是[a-z]*。除非修改,否则部分[a-z]是与集合a-z中的单个字符匹配的字符类;如果大于零,*量词的添加将贪婪地匹配尽可能多的字符 - 因此匹配'abc'但也允许零个字符匹配(或者字符集外的字符匹配)从0开始的位置是匹配的。)
在([a-z])*中添加分组有效地将量化集合中的匹配减少回单个字符,并返回集合中匹配的最后一个字符。
如果您想要分组效果(比如更复杂的模式),请使用非捕获组:
>>> re.findall(r'(?:[a-z])*', '123abc789')
['', '', '', 'abc', '', '', '', '']
答案 3 :(得分:1)
在第63行中,你找到了一个长度为1的字符组(用parens表示)的所有实例。*在这里没有做太多的事情(只是让你匹配零长度组) )。
在*旁边有[a-z]的其他示例中,您可以匹配任意长度的相邻字符。
修改
使用this tool可能会有所帮助。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?