如何解决PHP lookbehind固定宽度限制?
我在尝试匹配页面上特定字词之间找到的所有数字时遇到了问题。您将如何匹配以下文本中的所有数字,但只能在“开始”和“结束”之间进行匹配?
11
a
b
13
begin
t
899
y
50
f
end
91
h
这有效:
preg_match("/begin(.*?)end/s", $text, $out);
preg_match_all("/[0-9]{1,}/", $out[1], $result);
但是可以用一个表达式来完成吗?
我试过了,但它没有做到这一点
preg_match_all("/begin.*([0-9]{1,}).*end/s", $text, $out);
3 个答案:
答案 0 :(得分:7)
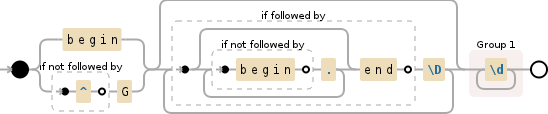
你可以像这样使用\G锚点,以及一些预测,以确保你没有“走出领土”(在两个词之间的区域之外):
(?:begin|(?!^)\G)(?:(?=(?:(?!begin).)*end)\D)*?(\d+)
(?: # Begin of first non-capture group
begin # Match 'begin'
| # Or
(?!^)\G # Start the match from the previous end of match
) # End of first non-capture group
(?: # Second non-capture group
(?= # Positive lookahead
(?:(?!begin).)* # Negative lookahead to prevent running into another 'begin'
end # And make sure that there's an 'end' ahead
) # End positive lookahead
\D # Match non-digits
)*? # Second non-capture group repeated many times, lazily
(\d+) # Capture digits
一个debuggex,如果这也有帮助:
答案 1 :(得分:0)
理想的解决方案
这里真正需要的是可变宽度的正面观察。正则表达式最终会像这样:
~(?<=begin.*)\d+(?=.*end)~s
但是,在撰写本文时,PHP正则表达式不支持此功能。仅支持固定宽度的后视镜。 (.Net风味确实如此)。
解决方法
为了实现我们的目标,我们可以将preg_replace_callback与以下正则表达式一起使用:
~(?<token>begin|end)|(?<number>\d+)|.*?~s
示例代码
function extract_number($input) {
function matchNumbers($match) {
static $in_region = false;
switch ($match['token']) {
case 'begin':
$in_region=true;
break;
case 'end':
$in_region=false;
break;
}
if ($in_region && isset($match['number'])) {
return $match['number'].',';
} else {
return '';
}
}
$ret=preg_replace_callback('~(?<token>begin|end)|(?<number>\d+)|.*?~s', 'matchNumbers', $input);
return array_filter(explode(',',$ret));
}
echo '<pre>';
echo var_dump(extract_number($str));
echo '</pre>';
输出(以OP为例)
array(3) {
[0]=>
string(3) "899"
[1]=>
string(2) "50"
}
答案 2 :(得分:0)
假设您的项目数据在文本中仅包含一个begin和end“标记”,则可以构建更直接,更有效的模式...
代码:(PHP Demo)(Pattern Demo)
$text = "11
a
b
13
begin
t
899
y
50
f
end
91
h";
var_export(preg_match_all('~(?:begin|\G(?!^))(?:(?!end)\D)+\K\d+~s', $text, $out) ? $out[0] : 'no matches');
输出:
array (
0 => '899',
1 => '50',
)
Layman的崩溃:
(?:begin|\G(?!^)) #match "begin" or continue matching from the position immediately after previous match
(?:(?!end)\D)*? #match zero or more occurrences of any non-digit character while screening for "end". If end is found, immediately cease pattern execution.
\K #restart the fullstring match from this position; this avoids the expense of using a capture group on the desired digits
\d+ #match one or more digits (as much as possible)
有关模式的更多学术细分,请参见“模式演示”链接。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?