反向传播训练卡住了
我正在尝试在Javascript中实现神经网络,我的项目的规范更喜欢实现为每个节点和层分别拥有对象。我是编程神经网络的新手,我在网络的反向传播训练中遇到了一些障碍。我似乎无法找到解释为什么反向传播算法不能为每个训练时期正确训练网络的原因。
我已经在一些网站上关注了教程,请确保尽可能密切关注:
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
以下是原始代码的链接: http://jsfiddle.net/Wkrgu/5/
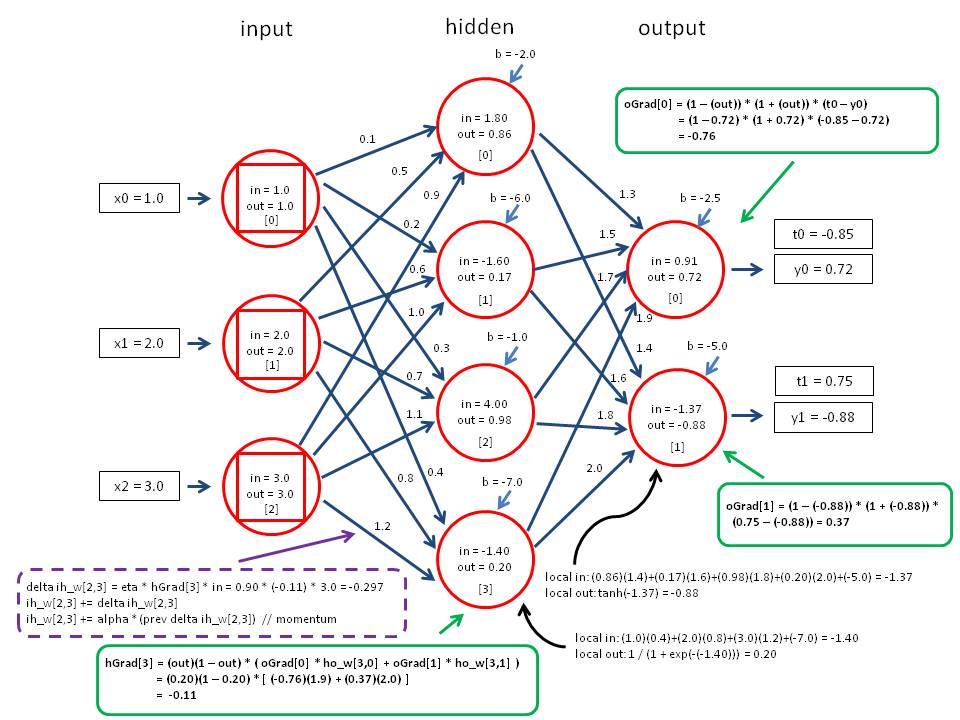
这是我想要做的,据我所知,这是我能解释的事情: 在计算每个节点/神经元的导数值和误差后,我正在实现这个功能:
// Once all gradients are calculated, work forward and calculate
// the new weights. w = w + (lr * df/de * in)
for(i = 0; i < this._layers.length; i++) {
// For each neuron in each layer, ...
for(j = 0; j < this._layers[i]._neurons.length; j++) {
neuron = this._layers[i]._neurons[j];
// Modify the bias.
neuron.bias += this.options.learningRate * neuron.gradient;
// For each weight, ...
for(k = 0; k < neuron.weights.length; k++) {
// Modify the weight by multiplying the weight by the
// learning rate and the input of the neuron preceding.
// If no preceding layer, then use the input layer.
neuron.deltas[k] = this.options.learningRate * neuron.gradient * (this._layers[i-1] ? this._layers[i-1]._neurons[k].input : input[k]);
neuron.weights[k] += neuron.deltas[k];
neuron.weights[k] += neuron.momentum * neuron.previousDeltas[k];
}
// Set previous delta values.
neuron.previousDeltas = neuron.deltas.slice();
}
}
渐变属性定义为:
error = 0.0;
// So for every neuron in the following layer, get the
// weight corresponding to this neuron.
for(k = 0; k < this._layers[i+1]._neurons.length; k++) {
// And multiply it by that neuron's gradient
// and add it to the error calculation.
error += this._layers[i+1]._neurons[k].weights[j] * this._layers[i+1]._neurons[k].gradient;
}
// Once you have the error calculation, multiply it by
// the derivative of the activation function to get
// the gradient of this neuron.
neuron.gradient = output * (1 - output) * error;
我的猜测是我正在更快地更新权重,或者我通过将它们完全乘以错误的值来更新它们。与我在这个主题上可以找到的公式相比,我觉得我非常彻底地遵循它们,但我显然做了一些非常错误的事情。
当我使用这个训练数据时,我得到了这些结果:
a.train([0,0], [0]);
a.train([0,1], [1]);
a.train([1,0], [1]);
console.log(a.input([0,0])); // [ 0.9960981505402279 ]
console.log(a.input([1,0])); // [ 0.9957925569461975 ]
console.log(a.input([0,1])); // [ 0.9964499429402672 ]
console.log(a.input([1,1])); // [ 0.996278252201647 ]
更新 以下是固定代码的链接:http://jsfiddle.net/adamthorpeg/aUF4c/3/ 注意:在每次输入都可以容忍错误之前不进行训练,因此有时一旦达到一个理想值的容许误差,结果仍会得到不准确的结果。为了对其进行全面训练,必须继续进行培训,直到所有错误都可以容忍。
1 个答案:
答案 0 :(得分:4)
我找到了问题的答案。答案是双重的:
首先,网络遭受了“灾难性遗忘”的问题。我一次在一个理想的值/输入对上进行训练,而不是在每对中循环训练,一次训练一个时期。
第二,在行中:
neuron.deltas[k] = this.options.learningRate * neuron.gradient * (this._layers[i-1] ? this._layers[i-1]._neurons[k].input : input[k]);
我将学习率和梯度(导数计算)乘以前一个神经元的输入值,而不是前一个神经元的输出值,这将是权重计算的输入。因此,该行的正确代码应为:
neuron.deltas[k] = this.options.learningRate * neuron.gradient * (this._layers[i-1] ? this._layers[i-1]._neurons[k].output : input[k]);
此资源非常宝贵:http://blog.zabarauskas.com/backpropagation-tutorial/
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?