正则表达式,用于查找一个前缀为偶数个相同字符的字符
我正在尝试匹配可能具有单引号字符(')的输入字符串。我的挑战是,我需要忽略目标字符之前的任何偶数引号字符,因为它们被认为是转义字符。
以下是我的想法。
(?=('')*)'
然而,这不适用于此目的。例如,如果我输入''',则正则表达式将匹配所有三个单引号字符,而不仅仅是最后一个。
以下是一些样本。
' ## match
'' ## no-match
''' ## matches the last quote character
'''' ## no-match
abc' ## matches the last quote character
Mike''s home' ## matches the last quote character only
非常感谢任何帮助。谢谢!
5 个答案:
答案 0 :(得分:2)
答案 1 :(得分:1)
基本上,您似乎想要检测包含至少一个奇数单引号字符序列的输入。
这是一个我相信会满足这个要求的正则表达式:
(^'|[^']')('')*([^']|$)
或者,简单地添加?:来抑制捕获组的等价物:
(?:^'|[^']')(?:'')*(?:[^']|$)
我编写了一个Perl程序来针对您提供的示例数据测试此正则表达式。 (我还添加了一些额外的样本输入。)请参阅以下内容,了解程序的预期输出以及程序本身。
预期输出:
* [']
* [x']
[x'']
* [x''']
['']
* [''x']
[''x'']
[''x''y]
* [''']
['''']
[''''x]
* [abc ']
* [Mike''s home']
[Mike''s home'']
* [Mike''s home''']
* [Mike''s home'''x]
[Mike''s home'''']
[Mike''s home''''x]
演示RegEx的Perl程序:
#/usr/bin/perl
use strict;
use warnings;
while (<DATA>) {
chomp;
my $match = " ";
if (/(^'|[^']')('')*([^']|$)/) {
# ^^ ^^^^^ ^^^^^ ^^^^ ^
# (1a) (1b) (2) 3a 3b
#
# Match the line if:
# (1a) The line begins with a single quote character
# -or-
# (1b) Somewhere contains a non-quote character followed by a single
# quote character
# (2) That is optionally followed by an even number of quote characters.
# (3a) And that is followed by a non-quote character
# -or-
# (3b) The end of the line.
$match = "* "
}
print "$match\[$_\]\n";
}
__END__
'
x'
x''
x'''
''
''x'
''x''
''x''y
'''
''''
''''x
abc '
Mike''s home'
Mike''s home''
Mike''s home'''
Mike''s home'''x
Mike''s home''''
Mike''s home''''x
答案 2 :(得分:1)
使用.net,您可以使用可变长度的lookbehind:
要找到一般引用偶数引号的最后一个引号:
(?<=^(?:[^']*'[^']*')*[^']*)'(?=[^']*$)
(你只需要在字符串的开头将子模式锚定在lookbehind内,并检查没有更多的引号,直到最后一个前瞻。)
对于您只需要匹配未转义的报价的特定情况,您只需使用:
(?<=(?<!')(?:'')*)'(?!')
(在这种情况下,不需要&#34;计算&#34;从字符串的开头到检查字符串直到结束,你只需要检查连续的字符。)
或没有嵌套的lookbehinds相同:
(?<=(?:^|[^'])(?:'')*)'(?!')
答案 3 :(得分:0)
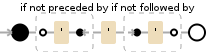
答案 4 :(得分:0)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?