Python re模块组匹配机制
问题形成
背景
在我阅读python2.7 redoc的教程时,它介绍了群组的行为:
groups()方法返回一个元组,其中包含所有子组的字符串,从1到多个子组。
问题
我清楚地了解这是如何单独运作的。但我可以理解以下例子:
>>> m = re.match("([abc])+","abc")
>>> m.groups()
('c',)
我的意思是,+不仅仅意味着一个或多个。如果是这样,则不应该使用正则表达式([abc])+ = ([abc])([abc])+(不是正式的BNF)。因此,结果应该是:
('a','b','c')
请详细说明背后的机制,谢谢。
P.S
我想学习正则表达式语言解释器,我该如何开始?书籍或正则表达式版本,谢谢!
3 个答案:
答案 0 :(得分:0)
基本上,正则表达式术语中引用的groups是正则表达式中定义的捕获组。
例如,在'([abc])+'中,只有一个捕获组,即([abc]),而像'([abc])([xyz])+'这样的组有2个组。
因此,在您的示例中,调用.groups()将始终返回长度为1的元组,因为这是正则表达式中存在的组数。
它没有返回您期望的结果的原因是因为您正在使用该组的重复运算符+ 。最终结果为causing the group to equal only the last match,因此仅保留最后一个匹配项(c)。另一方面,如果您使用了'([abc]+)'(注意+ 捕获组内),结果将是:
('abc',)
答案 1 :(得分:0)
一对分组括号形成一个组,即使它在量词内。如果一个组由于量词而多次匹配,则仅保存该组的最后一个匹配。该小组的成员人数不会与比赛一样多。
答案 2 :(得分:0)
嗯,我猜一张照片值1000字:
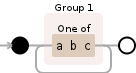
正在发生的事情是,正如您在自动机的可视化表示中看到的那样,您的正则表达式将一个或多个字符分组一次或多次,直到它到达匹配结束。然后最后一个角色进入小组。
如果您想获得所说的输出,则需要执行以下操作:
([abc])([abc])([abc])
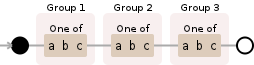
将匹配并在每个位置组合一个字符。
关于文档,我建议您阅读NFA的第一个理论和regexps。关于这个主题的MIT文档很不错:
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?