正则表达式,用于在Notepad ++中精确匹配单个数字后跟单词
:语句
假设我们有以下三条记录,我们只想匹配第一个仅 - 正好是一个数字后跟一个特定的单词,正则表达式可以用来制作它(在NotePad ++)?
- 2Cups
- 11Cups
- 222Cups
- 提案1:\ d {1}杯子
- 提案2:[^ 0-9] + [0-9]杯
我尝试过的表达方式和问题是:
它将分别在第二和第三条记录中找到“1Cups”和“2Cups”子串,这就是我们不想要的内容
与上述相同
(PS:记录可以是“XX 2Cups”,“YY22Cups”和“XYZ 333Cups”,即没有关于匹配部分位置的假设)
有什么建议吗?
:参考
[1] NotePad ++中的reg定义(与SciTe相同)
如Searching for a complex Regular Expression to use with Notepad++中所述,它是:http://www.scintilla.org/SciTERegEx.html
[2]匹配确切的位数
以下是一个示例:regular expression to match exactly 5 digits。
但是,我们不希望在此处找到更长记录中的可匹配子字符串。
5 个答案:
答案 0 :(得分:2)
如果字符串实际上有编号序列(1. 2Cups 2. 11Cups),你可以使用它后面的空格:
\s\d{1}Cups
如果之前没有编号列表,但字符串将位于该行的开头,则可以将其锚定在那里:
^\d{1}Cups
在Notepad ++ v6.5.1(Unicode)中测试。
答案 1 :(得分:1)
听起来你只想在字符串的开头匹配数字,或者如果它之前有空格,那么这样就可以了:
(^|\b)\dCups
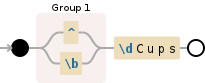
说明:
-
(^|\b)匹配字符串的开头或单词的开头(技术上,分词) -
\d匹配一个数字({1}是多余的) -
Cups比赛杯
答案 2 :(得分:0)
这将有效:
\b\dCups
如果“杯子”必须是一个完整的单词(即不匹配2Cupsizes:
\b\dCups\b
请注意,\b即使在输入的开头或结尾也匹配。
答案 3 :(得分:0)
我找到了一个可能的解决方案:
- 使用
^\d{1}Cups来匹配“从一个数字+杯子开始”案例,如Ken,Cottrell和Bohemian所建议的那样。 - 使用
[^\d]\dCups来匹配其他案例。
但是,还没有找到只使用一个正则表达式来解决问题的解决方案。
答案 4 :(得分:0)
尝试使用:
(?:^|\D)\dCups
只有在之前没有数字时才会匹配xCup。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?