如何找到正则表达式的所有猫
如何使用正则表达式查找所有“cat”?
“有些人在遇到问题时会想”我知道,我会用 正则表达式。“现在他们有两个问题!” (c)Jamie Zawinski
请帮助我通过一个查询找到div中的所有“cat”:)
cat
<div>let's try to find this cat and this cat</div>
cat
<div>let's try to find this cat and this cat</div>
cat
我做过这个,但是没有用:
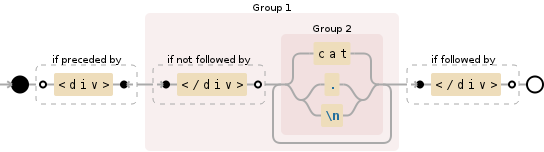
(?<=<div>)((?!<\/div>)(cat|(?:.|\n))+)(?=<\/div>)
当我使用Sublime Text时发现了这个问题。我们只能进行一次查询。可能吗?如果您可以使用任何编程语言(Python,PHP,JavaScript)回答,我也会很高兴。谢谢!
我可以找到最后一只猫,或者第一只猫,但需要找到所有坐在某些DIV中的猫。我想可能有其他语言的东西,但我只想要一个查询(一行) - 这对我来说最有趣。如果不可能,抱歉我的帖子:)
感谢@revo!非常好的变体,适用于Sublime Text。 让我为这个主题添加第二个问题...... Сan我们是用“猫”类的div来做的,但对于那些带有“狗”类的div来说却不行吗?
cat
<div class="cats">black cat, white cat</div>
cat
<div class="dogs">black cat, white cat</div>
cat
4 个答案:
答案 0 :(得分:1)
PHP模式:
$pattern = '~(?><div\b[^>]*+>|\G(?<!^))(?>[^c<]++|\Bc|c(?!at\b)|<(?!/div>))*+\Kcat~';
preg_match_all($pattern, $subject, $matches);
print_r($matches);
模式细节:
~ # pattern delimiter
(?> # atomic group: possible anchor
<div\b[^>]*+> # an opening div tag
| # OR
\G(?<!^) # a match contiguous to a precedent match
)
(?> # atomic group: all content between tags that is not "cat"
[^c<]++ # all characters except "c" or "<"
| # OR
\Bc # "c" not preceded by a word boundary
| # OR
c(?!at\b) # "c" not followed by "at" and a word boundary
| # OR
<(?!/div>) # "<" not followed by "/div>"
)*+ # repeat the group zero or more times
\K # reset all that has been matched before from match result
cat # literal: cat
~
使用DOM:
$dom = new DOMDocument();
@$dom->loadHTML($yourHtml);
$divs = $dom->getElementsByTagName('div');
foreach($divs as $div) {
preg_match_all('~\bcat\b~', $div->textContent, $matches);
print_r($matches);
}
答案 1 :(得分:1)
这适用于Sublime Text:
(?s)(cat)(?=[^>]*?</div>)

答案 2 :(得分:0)
考虑到您没有指定需要使用哪种语言,我将使用JavaScript来解决此问题。
你可以用一个简单的技巧来做,它可以删除所有垃圾:
var string = "<div>let's try to find this cat and this cat</div>\n<div>let's try to find this cat and this cat</div>\nanother cat";
var str = string.replace(/(^|<\/div>)[\w\W]*?(<div>|$)/g,''); //filters out anything outside divs
console.log(str.match(/cat/g)); // ["cat", "cat", "cat", "cat"]
在一行中,这将是:
console.log("<div>let's try to find this cat and this cat</div>\n<div>let's try to find this cat and this cat</div>\nanother cat".replace(/(^|<\/div>)[\w\W]*?(<div>|$)/g,'').match(/cat/g)); // ["cat", "cat", "cat", "cat"]
即使您需要匹配以下内容,也可以使其工作:
<div class="foo"><div></div>cat</div>
我会使用以下内容:
var str = "<div>let's try to find this cat and this cat</div>\n<div>let's try to find this cat and this cat</div>\nanother cat\n<div class=\"foo\"><div></div>and a cat</div>";
var openCounter = 0;
var result = [];
for (var i=0;i<str.length;i++) {
if (str.substr(i,4) == '<div') openCounter++;
else if (str.substr(i,6) == '</div>') openCounter = Math.max(0,openCounter-1); //don't go lower than 0
if (openCounter > 0 && str.substr(i,3) == 'cat') result.push([str.substr(i,3), i]);
}
console.log(JSON.stringify(result)); //[["cat",28],["cat",41],["cat",79],["cat",92],["cat",148]]
这也获得了在字符串中找到cat的索引,并将其与cat一起存储在result变量中。
答案 3 :(得分:0)
使用正则表达式无法可靠地完成(正如其他人提到的那样)。
原因是HTML可以包含嵌套标签,但正则表达式无法“计算”您有多少级别,因此您总是能够构建一些示例正则表达式找不到所有猫的HTML示例。
对于解析HTML,您需要使用STACK来跟踪标记内的深度。在这个python示例中,我使用序列(self.tags)作为堆栈:
from HTMLParser import HTMLParser
import re
# create a subclass and override the handler methods
class MyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.tags = []
def handle_starttag(self, tag, attrs):
self.tags.append(tag)
def handle_endtag(self, tag):
self.tags.pop()
def handle_data(self, data):
if self.tags and self.tags[-1] == 'div':
# now we are dealing with a single string.
# use a regular expression to find all cats
num = len(re.findall('cat', data))
if num:
print 'found %d cats at %s' % (num, '.'.join(self.tags))
# instantiate the parser and fed it some HTML
parser = MyHTMLParser()
parser.feed('''
cat
<div>let's try to find this cat and this cat</div>
cat
<div>let's try to find this cat and this cat</div>
cat
''')
# now try a trickier example
parser.feed('''<body><div>cat<div>another text</div></div></body>''')
输出:
found 2 cats at div
found 2 cats at div
found 1 cats at body.div
这也很容易扩展到只匹配基于class属性的特定div。
(参见attrs的{{1}}参数)。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?