RegEx for Javascript允许除“和%之外的所有内容
在正则表达式中:
var r = new RegExp('^[^%"]*$');
^和$表示什么?这是否意味着字符串的开头和结尾或其他内容。
如果我删除^和$之类的内容,那该怎么办?
var r = new RegExp('[^%"]*');
这是一个有效的正则表达式吗?
3 个答案:
答案 0 :(得分:2)
^和$表示什么?这是否意味着字符串的开头和结尾 别的什么。
在[]字符类之外,^匹配行的开头,$匹配行的结尾。在[]字符类中,^(在类的开头使用时)表示计算不在字符类中的任何字符。
另外如果我删除^和$之类的东西:var r = new RegExp('[^%“] *');?这是一个有效的正则表达式吗?
是的,这是有效的,只是因为在否定匹配的任一侧可能有字符,并且*匹配定义的字符类的0或更多字符,所以它不会有多大成就。
使用类似regex101.com to test your expressions and play around的内容。
答案 1 :(得分:0)
是'^'和'$'分别表示字符串的结尾。至少在一个角色类之外。在一个字符类^意味着没有,所以它将不匹配那些否定的字符(在这种情况下%和单引号)
如果您删除了^和$,那么正则字符串可能会通过,即使字符串中包含%或“,其他字符
实施例
"\"50\"%".match(/^[^"%]*$/); // equals null
"\"50\"%".match(/[^"%]*/); //equals [""]
"\"50\"%".match(/[^"%]*/g); //equals ["", "50", "", "", ""]
同样在JS中,最佳做法是使用/ some regex / gm而不是新的Regex(“Some regex”)来创建正则表达式
答案 2 :(得分:0)
可以使用^标记值更改$和m的含义。
- 如果设置了
m标记,^和$将分别匹配行的开头和结尾。 - 如果未设置
m标记,^和$将分别匹配整个字符串的开头和结尾。
由于图像优于1000个单词,因此这里是正则表达式:
^[^%"]*$
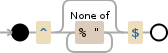
[^%"]*
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?