如何在Neo4J中处理队列?
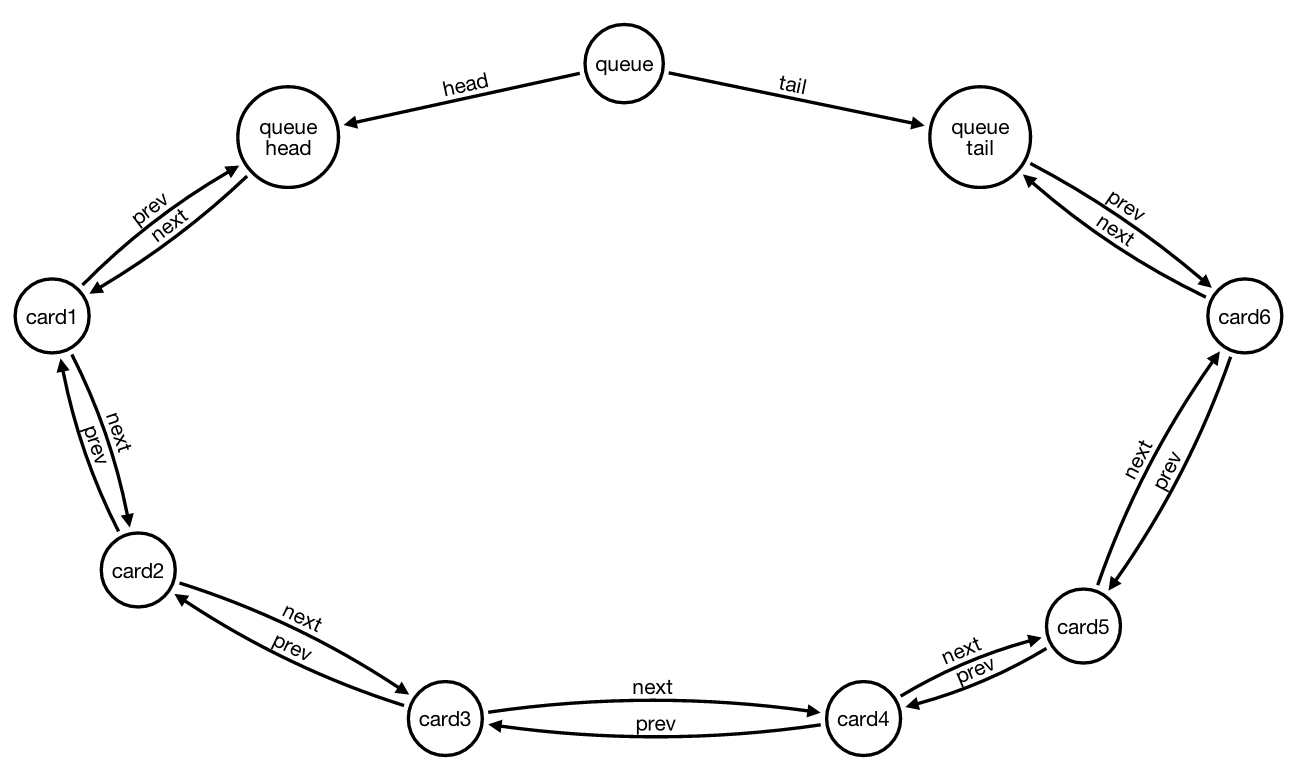
在我的Neo4J数据库中,我有一系列通过双链表实现的卡片队列。数据结构显示在下图中(使用Alistair Jones' Arrows在线工具生成的队列的SVG图表):

由于这些是队列,我总是从队列的TAIL添加新项目。我知道双关系(下一个/上一个)不是必需的,但是它们简化了两个方向的遍历,所以我更喜欢它们。
插入新节点
这是我用来插入新"卡":
的查询MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
查询可以分为两部分。在第一部分:
MATCH (currentList:List)-[currentTailRel:TailCard]->(currentTail:Card) WHERE ID(currentList) = {{LIST_ID}}
CREATE (currentList)-[newTailRel:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (newCard)-[newPrevRel:PreviousCard]->(currentTail)
CREATE (currentTail)-[newNextRel:NextCard]->(newCard)
DELETE currentTailRel
我处理将卡添加到已有其他卡的队列的一般情况。 在第二部分:
WITH count(newCard) as countNewCard
WHERE countNewCard = 0
MATCH (emptyList:List)-[fakeTailRel:TailCard]->(emptyList),
(emptyList)-[fakeHeadRel:HeadCard]->(emptyList)
WHERE ID(emptyList) = {{LIST_ID}}
WITH emptyList, fakeTailRel, fakeHeadRel
CREATE (emptyList)-[:TailCard]->(newCard:Card { title: {{TITLE}}, description: {{DESCRIPTION}} })
CREATE (emptyList)-[:HeadCard]->(newCard)
DELETE fakeTailRel, fakeHeadRel
RETURN true
我处理队列中没有卡片的情况。在这种情况下,(emptyList)节点有两个类型为HeadCard和TailCard的关系,指向它自己(我称之为假尾和假头)。
这似乎有效。尽管如此,作为一个菜鸟,我有一种感觉,我正在过度思考事物,并且可能有更优雅和直接的方式来实现这一目标。例如,我想要以更好/更简单的方式理解如何做的一件事是如何分离两个子查询。如果可能,我还希望能够在两种情况下都返回新创建的节点。
存档现有节点
以下是我从队列中删除节点的方法。我从不想简单地删除节点,而是将它们添加到存档节点,以便在需要时可以恢复它们。 我已经确定了这些案例:
当要归档的节点位于队列的中间
时// archive a node in the middle of a doubly-linked list
MATCH (before:Card)-[n1:NextCard]->(middle:Card)-[n2:NextCard]->(after:Card)
WHERE ID(middle)=48
CREATE (before)-[:NextCard]->(after)
CREATE (after)-[:PreviousCard]->(before)
WITH middle, before, after
MATCH (middle)-[r]-(n)
DELETE r
WITH middle, before, after
MATCH (before)<-[:NextCard*]-(c:Card)<-[:HeadCard]-(l:List)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(middle)
RETURN middle
当要归档的节点是队列的 head 时
// archive the head node of a doubly-linked list
MATCH (list:List)-[h1:HeadCard]->(head:Card)-[n1:NextCard]->(second:Card)
WHERE ID(head)=48
CREATE (list)-[:HeadCard]->(second)
WITH head, list
MATCH (head)-[r]-(n)
DELETE r
WITH head, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(head)
RETURN head
当要归档的节点是队列的尾时
// archive the tail node of a doubly-linked list
MATCH (list:List)-[t1:TailCard]->(tail:Card)-[p1:PreviousCard]->(nextToLast:Card)
WHERE ID(tail)=48
CREATE (list)-[:TailCard]->(nextToLast)
WITH tail, list
MATCH (tail)-[r]-(n)
DELETE r
WITH tail, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(tail)
RETURN tail
当要归档的节点是队列中 only 节点
时// archive the one and only node in the doubly-linked list
MATCH (list:List)-[tc:TailCard]->(only:Card)<-[hc:HeadCard]-(list:List)
WHERE ID(only)=48
CREATE (list)-[:TailCard]->(list)
CREATE (list)-[:HeadCard]->(list)
WITH only, list
MATCH (only)-[r]-(n)
DELETE r
WITH only, list
MATCH (list)<-[:NextList*]-(fl:List)<-[:HeadList]-(p:Project)-[:ArchiveList]->(archive:List)
CREATE (archive)-[r:Archived { archivedOn : timestamp() }]->(only)
RETURN only
我已经尝试过多种方法将以下cypher查询合并为一个,使用WITH语句,但我没有成功。我目前的计划是一个接一个地运行所有4个查询。实际上只有一个人会做某事(即归档节点)。
有什么建议可以让它变得更好,更精简吗?我甚至愿意重组数据结构,因为这是我为自己创建的沙盒项目,学习Angular和Neo4J,所以最终的目标是学习如何更好地做事:)
也许数据结构本身可以改进?考虑到在队列末尾插入/存档节点有多复杂,我只能想象在队列中移动元素会有多困难(我的自我项目的一个要求是能够重新排序元素)每当需要时队列)。
编辑:
仍在尝试合并这4个查询。 我得到了这个:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard, before, btc, tca, after, listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
在找不到内容时返回NULL,在找到内容时返回节点/关系。我认为这可能是一个很好的起点,所以我添加了以下内容:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
WITH theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
FOREACH (value IN beforeList | CREATE (before)-[:NEXT_CARD]->(after))
FOREACH (value IN beforeList | CREATE (after)-[:PREV_CARD]->(before))
FOREACH (value IN beforeList | DELETE btc)
FOREACH (value IN beforeList | DELETE tca)
RETURN theCard
当我执行此操作时(选择了ID作为before=NULL,我的笔记本电脑的粉丝开始疯狂地旋转,查询永远不会返回,最终neo4j浏览器说它已经失去了与服务器的连接。结束查询的唯一方法是停止服务器。
所以我将查询更改为更简单:
MATCH (theCard:Card) WHERE ID(theCard)=22
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)
RETURN theCard,
CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList,
before, btc, tca, after,
listOfOne, lootc, tcloo, listToHead, lthtc, tcs, second, listToTail, ltttc, tcntl, nextToLast
我仍然在一个无限循环或某事......
所以我想行CASE WHEN before IS NULL THEN [] ELSE COLLECT(before) END AS beforeList并不是一个好主意......有关如何从这里开始的任何建议吗?我走错了路吗?
解决方案?
最后,经过大量研究,我发现了一种编写单个查询的方法,可以处理所有可能的场景。我不知道这是否是实现我想要实现的目标的最佳方式,但它对我来说似乎优雅而紧凑。你觉得怎么样?
// first let's get a hold of the card we want to archive
MATCH (theCard:Card) WHERE ID(theCard)=44
// next, let's get a hold of the correspondent archive list node, since we need to move the card in that list
OPTIONAL MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(theList:List)<-[:NEXT_LIST|HEAD_LIST*]-(theProject:Project)-[:ARCHIVE_LIST]->(theArchive:List)
// let's check if we are in the case where the card to be archived is in the middle of a list
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (next:Card)-[ntc:PREV_CARD]->(theCard:Card)-[tcp:PREV_CARD]->(previous:Card)
// let's check if the card to be archived is the only card in the list
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)<-[tcloo:HEAD_CARD]-(listOfOne:List)
// let's check if the card to be archived is at the head of the list
OPTIONAL MATCH (listToHead:List)-[lthtc:HEAD_CARD]->(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)-[stc:PREV_CARD]->(theCard:Card)
// let's check if the card to be archived is at the tail of the list
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)-[ntltc:NEXT_CARD]->(theCard:Card)
WITH
theCard, theList, theProject, theArchive,
CASE WHEN theArchive IS NULL THEN [] ELSE [(theArchive)] END AS archives,
CASE WHEN before IS NULL THEN [] ELSE [(before)] END AS befores,
before, btc, tca, after,
CASE WHEN next IS NULL THEN [] ELSE [(next)] END AS nexts,
next, ntc, tcp, previous,
CASE WHEN listOfOne IS NULL THEN [] ELSE [(listOfOne)] END AS listsOfOne,
listOfOne, lootc, tcloo,
CASE WHEN listToHead IS NULL THEN [] ELSE [(listToHead)] END AS listsToHead,
listToHead, lthtc, tcs, second, stc,
CASE WHEN listToTail IS NULL THEN [] ELSE [(listToTail)] END AS listsToTail,
listToTail, ltttc, tcntl, nextToLast, ntltc
// let's handle the case in which the archived card was in the middle of a list
FOREACH (value IN befores |
CREATE (before)-[:NEXT_CARD]->(after)
CREATE (after)-[:PREV_CARD]->(before)
DELETE btc, tca)
FOREACH (value IN nexts | DELETE ntc, tcp)
// let's handle the case in which the archived card was the one and only card in the list
FOREACH (value IN listsOfOne |
CREATE (listOfOne)-[:HEAD_CARD]->(listOfOne)
CREATE (listOfOne)-[:TAIL_CARD]->(listOfOne)
DELETE lootc, tcloo)
// let's handle the case in which the archived card was at the head of the list
FOREACH (value IN listsToHead |
CREATE (listToHead)-[:HEAD_CARD]->(second)
DELETE lthtc, tcs, stc)
// let's handle the case in which the archived card was at the tail of the list
FOREACH (value IN listsToTail |
CREATE (listToTail)-[:TAIL_CARD]->(nextToLast)
DELETE ltttc, tcntl, ntltc)
// finally, let's move the card in the archive
// first get a hold of the archive list to which we want to add the card
WITH
theCard,
theArchive
// first get a hold of the list to which we want to add the new card
OPTIONAL MATCH (theArchive)-[tact:TAIL_CARD]->(currentTail:Card)
// check if the list is empty
OPTIONAL MATCH (theArchive)-[tata1:TAIL_CARD]->(theArchive)-[tata2:HEAD_CARD]->(theArchive)
WITH
theArchive, theCard,
CASE WHEN currentTail IS NULL THEN [] ELSE [(currentTail)] END AS currentTails,
currentTail, tact,
CASE WHEN tata1 IS NULL THEN [] ELSE [(theArchive)] END AS emptyLists,
tata1, tata2
// handle the case in which the list already had at least one card
FOREACH (value IN currentTails |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theCard)-[:PREV_CARD]->(currentTail)
CREATE (currentTail)-[:NEXT_CARD]->(theCard)
DELETE tact)
// handle the case in which the list was empty
FOREACH (value IN emptyLists |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theArchive)-[:HEAD_CARD]->(theCard)
DELETE tata1, tata2)
RETURN theCard
最后编辑
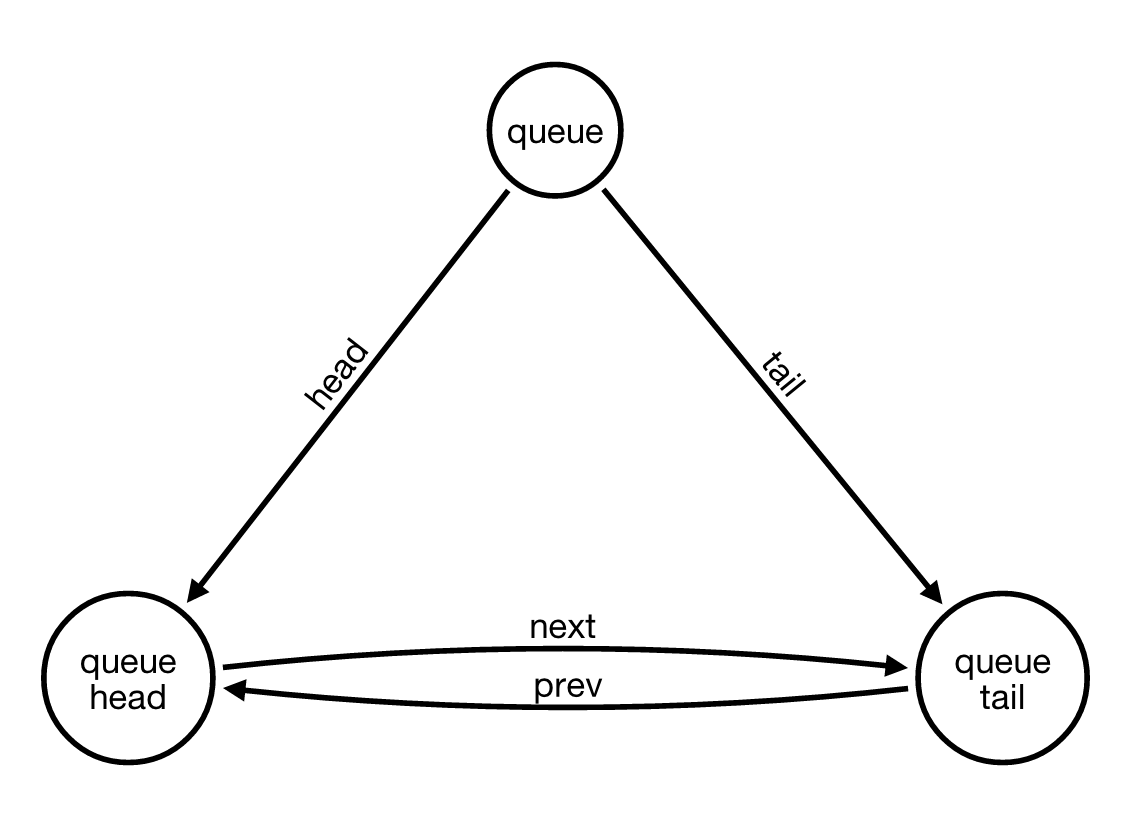
根据Wes的建议,我决定改变应用程序中每个队列的处理方式,添加两个额外的节点, head 和 tail 。
插入新卡
将 head 和 tail 的概念从简单关系移动到节点允许在插入新卡时具有单个案例。即使在空队列的特殊情况下......
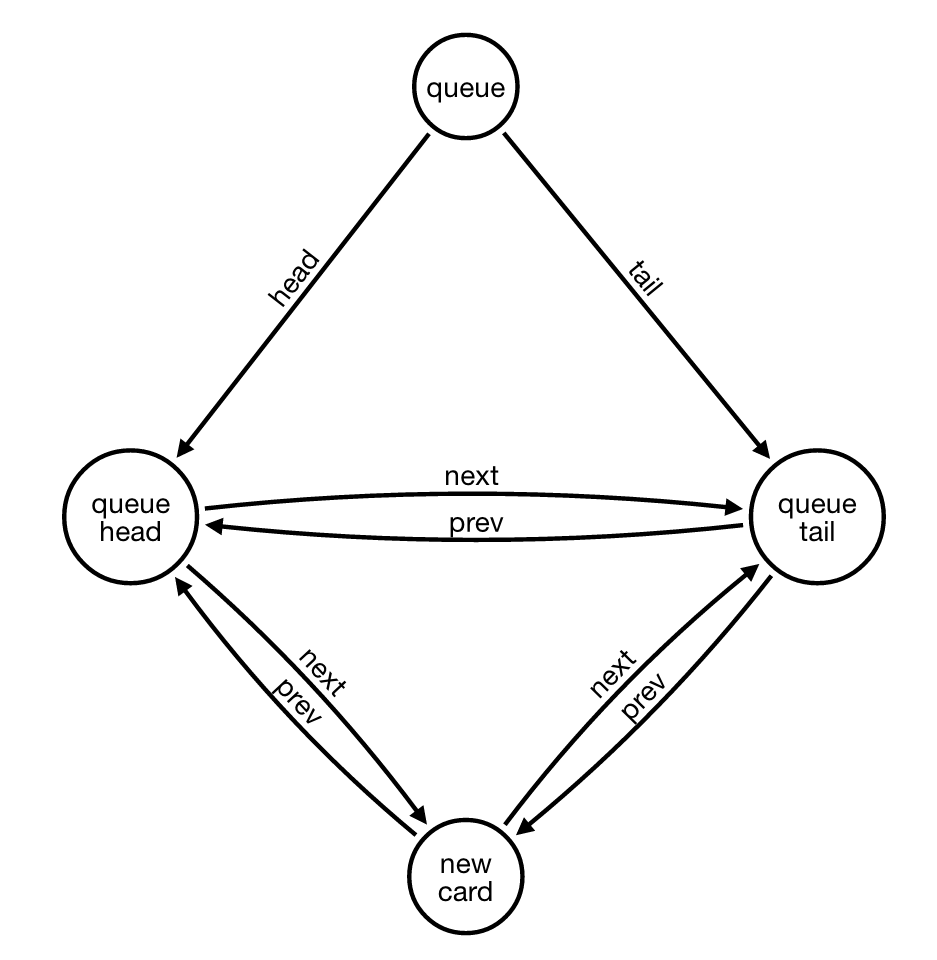
我们要做的就是在队列的尾部添加一张新卡:
- 找到[PREV_CARD]连接的(上一个)节点和[NEXT_CARD]关系到队列的(尾部)节点
- 创建(newCard)节点
- 使用[PREV_CARD]和[NEXT_CARD]关系将(newCard)节点连接到(tail)节点
- 使用[PREV_CARD]和[NEXT_CARD]关系将(newCard)节点连接到(上一个)节点
- 最后删除将(上一个)节点连接到队列的(尾部)节点的原始[PREV_CARD]和[NEXT_CARD]关系
转换为以下cypher查询:
MATCH (theList:List)-[tlt:TAIL_CARD]->(tail)-[tp:PREV_CARD]->(previous)-[pt:NEXT_CARD]->(tail)
WHERE ID(theList)={{listId}}
WITH theList, tail, tp, pt, previous
CREATE (newCard:Card { title: "Card Title", description: "" })
CREATE (tail)-[:PREV_CARD]->(newCard)-[:NEXT_CARD]->(tail)
CREATE (newCard)-[:PREV_CARD]->(previous)-[:NEXT_CARD]->(newCard)
DELETE tp,pt
RETURN newCard
存档卡
现在让我们重新考虑我们要存档卡片的用例。让我们回顾一下架构:
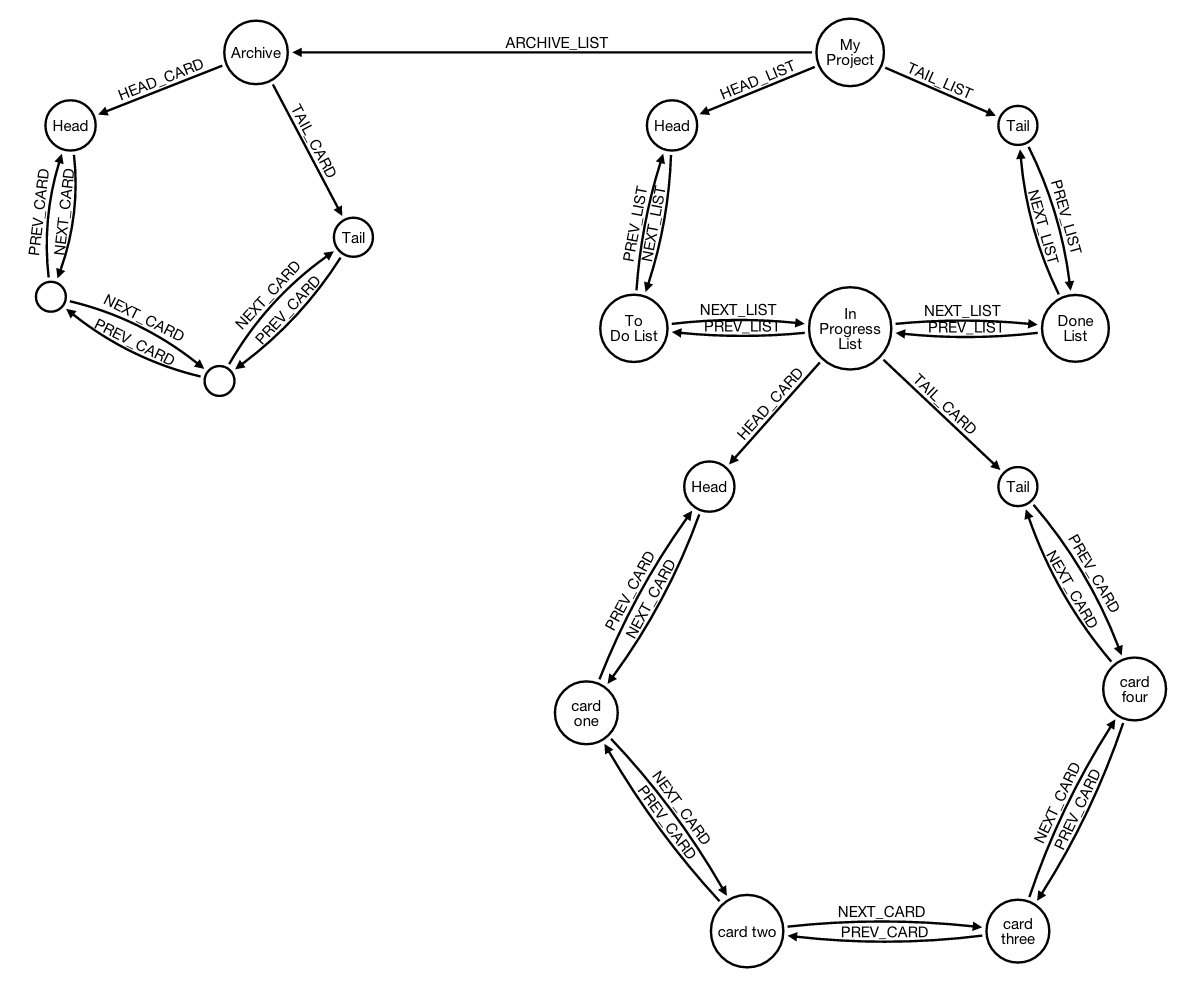
我们有:
- 每个项目都有列表 的队列
- 每个项目都有一个存档队列来存储所有存档的卡
- 每个列表都有卡 的队列
在之前的队列架构中,我有4种不同的场景,具体取决于要归档的卡是头部,尾部还是中间的卡,或者它是否是在Quee中留下的最后一张卡。
现在,随着 head 和 tail 节点的引入,只有一个场景,因为头部和尾部节点都在那里,即使在队列为空的情况:
- 我们需要在(theCard)节点之前和之后找到(上一个)和(下一个)节点,该节点是我们要归档的节点
- 然后,我们需要连接(上一个)和(下一个)[NEXT_CARD]和[PREV_CARD]关系
- 然后,我们需要删除所有连接(theCard)到(前一个)和(下一个)节点的关系
生成的密码查询可以细分为三个不同的部分。第一部分负责找到(theArchive)节点,给定(theCard)节点的ID:
MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(l:List)<-[:NEXT_LIST*]-(h)<-[:HEAD_LIST]-(p:Project)-[:ARCHIVE]->(theArchive:Archive)
WHERE ID(theCard)={{cardId}}
接下来,我们执行前面几行描述的逻辑:
WITH theCard, theArchive
MATCH (previous)-[ptc:NEXT_CARD]->(theCard)-[tcn:NEXT_CARD]->(next)-[ntc:PREV_CARD]->(theCard)-[tcp:PREV_CARD]->(previous)
WITH theCard, theArchive, previous, next, ptc, tcn, ntc, tcp
CREATE (previous)-[:NEXT_CARD]->(next)-[:PREV_CARD]->(previous)
DELETE ptc, tcn, ntc, tcp
最后,我们在存档队列的尾部插入(theCard):
WITH theCard, theArchive
MATCH (theArchive)-[tat:TAIL_CARD]->(archiveTail)-[tp:PREV_CARD]->(archivePrevious)-[pt:NEXT_CARD]->(archiveTail)
WITH theCard, theArchive, archiveTail, tp, pt, archivePrevious
CREATE (archiveTail)-[:PREV_CARD]->(theCard)-[:NEXT_CARD]->(archiveTail)
CREATE (theCard)-[:PREV_CARD]->(archivePrevious)-[:NEXT_CARD]->(theCard)
DELETE tp,pt
RETURN theCard
我希望你找到这个有趣的内容,因为我找到了这个练习。我想再次感谢Wes在这个有趣的(至少对我来说)实验中提供的远程帮助(通过Twitter和Stack Overflow)。
2 个答案:
答案 0 :(得分:2)
一个不错的问题 - 图中的双向链表。我最近研究了一个类似的概念,我需要跟踪列表,但试图找到一种方法来避免需要知道如何处理列表边缘情况的结束的困难。我努力的结果是this graph gist about skip lists in cypher.
翻译成双向链表,这看起来像是:
CREATE
(head:Head),
(tail:Tail),
(head)-[:NEXT]->(tail),
(tail)-[:PREV]->(head),
(a:Archive)-[:NEXT]->(:ArchiveTail)-[:PREV]->(a);
; // we need something to start at, and an archive list
然后你可以用简单的方法对节点进行排队:
MATCH (tail:Tail)-[p:PREV]->(prev),
(tail)<-[n:NEXT]-(prev)
CREATE (new {text:"new card"})<-[:NEXT]-(prev),
(new)-[:PREV]->(prev),
(new)<-[:PREV]-(tail),
(new)-[:NEXT]->(tail)
DELETE p, n
归档节点非常简单:
MATCH (toArchive)-[nn:NEXT]->(next),
(toArchive)<-[np:PREV]-(next),
(toArchive)<-[pn:NEXT]-(prev),
(toArchive)-[pp:PREV]->(prev)
WHERE toArchive.text = "new card 2"
CREATE (prev)-[:NEXT]->(next)-[:PREV]->(prev)
DELETE nn, np, pn, pp
WITH toArchive
MATCH (archive:Archive)-[n:NEXT]->(first)-[p:PREV]->(archive)
CREATE (archive)-[:NEXT]->(toArchive)<-[:PREV]-(first),
(archive)<-[:PREV]-(toArchive)-[:NEXT]->(first)
DELETE n, p
您的用例实际上比跳过列表在算法上容易得多,因为您可以通过保持尾部直接将卡排到末尾来避免对varlength路径的大多数需求。希望其他人实施类似的想法会发现你的SO问题很有用。
答案 1 :(得分:1)
您的解决方案看起来很不错,也符合您的目的。我只是为你添加一些建议......当你检查要归档的卡片是在列表中间并确认它在中间时,你不需要检查它是否在头部或列表的尾部,反之亦然。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?