用于匹配拼音的正则表达式
我正在寻找能够正确匹配有效拼音的正则表达式(例如“sheng”,“sou”(同时忽略无效的拼音,例如“shong”,“sei”)。大多数正则表达式提供在顶部在某些情况下,Google搜索结果与无效拼音匹配。
显然,无论采用何种方法,这将是一个怪物正则表达式,我对解决这个问题可以采取的不同方法特别感兴趣。例如,“Optimizing a regular expression to parse chinese pinyin”使用了回溯。
可在此处找到有效拼音表: http://pinyin.info/rules/initials_finals.html
2 个答案:
答案 0 :(得分:7)
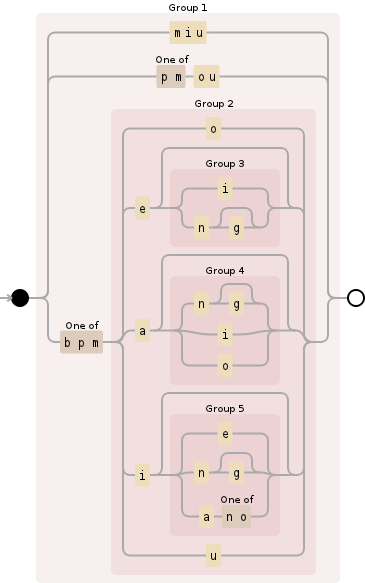
我去了一个正则表达式,用拼音的首字母(通常是第一个字母)分组较小的正则表达式。所以,第一组包括所有“b”,“p”和“m”声音,然后是“f”,然后是“d”和“t”等。
这种方法似乎易于阅读,并且应该易于编辑(如果需要更正或添加)。我还为群体的乞讨添加了例外以提高可读性。
([mM]iu|[pmPM]ou|[bpmBPM](o|e(i|ng?)?|a(ng?|i|o)?|i(e|ng?|a[no])?|u))|
([fF](ou?|[ae](ng?|i)?|u))|([dD](e(i|ng?)|i(a[on]?|u))|
[dtDT](a(i|ng?|o)?|e(i|ng)?|i(a[on]?|e|ng|u)?|o(ng?|u)|u(o|i|an?|n)?))|
([nN]eng?|[lnLN](a(i|ng?|o)?|e(i|ng)?|i(ang|a[on]?|e|ng?|u)?|o(ng?|u)|u(o|i|an?|n)?|ve?))|
([ghkGHK](a(i|ng?|o)?|e(i|ng?)?|o(u|ng)|u(a(i|ng?)?|i|n|o)?))|
([zZ]h?ei|[czCZ]h?(e(ng?)?|o(ng?|u)?|ao|u?a(i|ng?)?|u?(o|i|n)?))|
([sS]ong|[sS]hua(i|ng?)?|[sS]hei|[sS][h]?(a(i|ng?|o)?|en?g?|ou|u(a?n|o|i)?|i))|
([rR]([ae]ng?|i|e|ao|ou|ong|u[oin]|ua?n?))|
([jqxJQX](i(a(o|ng?)?|[eu]|ong|ng?)?|u(e|a?n)?))|
(([aA](i|o|ng?)?|[oO]u?|[eE](i|ng?|r)?))|
([wW](a(i|ng?)?|o|e(i|ng?)?|u))|
[yY](a(o|ng?)?|e|in?g?|o(u|ng)?|u(e|a?n)?)
这是我创建的Debuggex example。
答案 1 :(得分:2)
我会使用不仅仅是正则表达式的组合方法。
检查有效的拼音:
-
抓住词语
-
只要它们是辅音,就从单词的开头抓取字母。这将初始声音与最终声音分开。
-
检查初始和最终是否有效......
-
...如果是这样,看看是否允许他们的组合(通过像this这样的表,但条目只是1和0)。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?