正则表达式匹配一个或两个引号,但不是连续三个
对于我的生活,我无法理解这一点。
我需要搜索以下文字,只匹配粗体引号:
不匹配:“”“这是一个python docstring”“”
匹配:“这是常规字符串”
匹配:“”←这是一个空字符串
如何使用正则表达式执行此操作?
这是我尝试过的:
不起作用:
(?!"")"(?<!"")
关闭,但不匹配双引号。
不起作用:
"(?<!""")|(?!"")"(?<!"")|(?!""")"
我天真地认为我可以添加我不想要的替代品,但逻辑最终会逆转。这个匹配所有内容,因为所有引号都至少与其中一个替换匹配。
(请注意:我没有运行代码,因此使用__doc__的解决方案无济于事,我只是想在我的代码编辑器中查找和替换。)
2 个答案:
答案 0 :(得分:16)
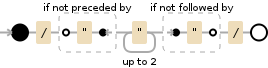
您可以使用/(?<!")"{1,2}(?!")/
<强>尸检:
-
(?<!")文字"的负面观察。匹配不能在前面有这个角色 -
"{1,2}文字"匹配一次或两次 -
(?!")文字"的否定前瞻。匹配 之后不能拥有此字符
您的第一次尝试可能会失败,因为(?!")是负面的预测,(?<!")是负面的后瞻。在比赛开始之前预测,或者在比赛结束后看后卫是没有意义的。
答案 1 :(得分:1)
我意识到我原来的问题描述实际上有些错误。也就是说,我需要仅匹配单个引号字符,除非它是 3 引号字符组的一部分。
不同之处在于,这对于编辑是可取的,这样我就可以找到并替换为'。如果我匹配“一两个引号”,那么我就无法自动替换为单个字符。
我想出了满足这种情况的h20000000's answer的修改:
(?<!"")(?<=(?!""").)"(?!"")
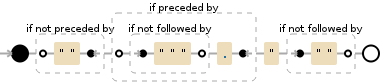
在demo中,您可以看到""是单独匹配的,而不是作为一个组匹配的。
这与其他答案非常相似,除了:
- 它只匹配一个
" -
让我们匹配我们想要的所有内容,除了仍匹配
"""的中间引号:
-
最后,添加
(?<=(?!""").)特别排除了这种情况,通过说“回顾一个字符,如果接下来的三个字符是""",则匹配失败”:
我决定不改变这个问题,因为我不想劫持答案,但我认为这可能是一个有用的补充。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?