查找不是HTML属性或超链接标记内容的所有URL
我正在试图找出一个匹配所有不属于元素属性或是超链接内容的URL的正则表达式。
应匹配:
1. This is a url http://www.google.com
不应该匹配:
1. <a href="http://www.google.com">Google</a>
2. <a href="http://www.google.com">http://www.google.com</a>
3. <img src="http://www.google.com/image.jpg">
4. <div data-url="http://www.google.com"></div>
我目前正在使用这个正则表达式来匹配所有网址,我想我知道我要检测什么,但我无法弄清楚使用正则表达式。
\\b(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@#/%=~_|]
EDITED
我想要实现的目标如下。我想转换这个字符串。
This is a url http://www.google.com <a href="http://www.google.com" title="Go to Google">Google</a><a href="http://www.google.com">http://www.google.com</a><img src="http://www.google.com/image.jpg"><div data-url="http://www.google.com"></div>
要
This is a url <a href="http://www.google.com">http://www.google.com</a> <a href="http://www.google.com" title="Go to Google">Google</a><a href="http://www.google.com">http://www.google.com</a><img src="http://www.google.com/image.jpg"><div data-url="http://www.google.com"></div>
通过删除标记然后将它们放回来进行预处理并不能解决问题,因为实际上最终会删除现有超链接元素的所有数据属性。当在href旁边的其他属性中使用其他URL时,它也无法解决问题。
到目前为止,我还没有找到任何人建议的解决方案,到目前为止我还没有找到使用HTML解析器执行此操作的方法。实际上,使用正则表达式似乎更有用。
已编辑2
根据Dean的建议尝试后,我准备排除HTML解析器能够实现这一点,因为它无法处理字符串而不使其成为有效的HTML文档。这是基于建议示例的代码+处理排除案例2的修复。
Document doc = Jsoup.parseBodyFragment(htmlText);
final List<TextNode> nodesToChange = new ArrayList<TextNode>();
NodeTraversor nd = new NodeTraversor(new NodeVisitor() {
@Override
public void tail(Node node, int depth) {
if (node instanceof TextNode) {
TextNode textNode = (TextNode) node;
Node parent = node.parent();
if(parent.nodeName().equals("a")){
return;
}
String text = textNode.getWholeText();
List<String> allMatches = new ArrayList<String>();
Matcher m = Pattern.compile("\\b(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@#/%=~_|]")
.matcher(text);
while (m.find()) {
allMatches.add(m.group());
}
if(allMatches.size() > 0){
nodesToChange.add(textNode);
}
}
}
@Override
public void head(Node node, int depth) {
}
});
nd.traverse(doc.body());
此代码将HTML,HEAD和BODY标记添加到结果中。我能解决这个问题的唯一方法是检查字符串中是否存在HTML,HEAD和BODY标记。如果没有,请在处理后将它们分开。
我希望别人有比这个黑客更好的建议。在处理时间方面使用JSOUP已经非常昂贵,所以如果我不需要,我真的不想增加更多的开销。
3 个答案:
答案 0 :(得分:1)
期待有效的HTML输出
以下是帮助您入门的粗略指南。
- 使用像jsoup Java HTML Parser这样的HTML5解析引擎
- HTML5规范以已知的指定方式处理无效HTML,以获得可预测的结果。
- 这个解析引擎实际上也提供了HTML修改方法。
-
解析你的HTML:
String html = "This is a url http://www.google.com <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a>"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body(); - 找到所有文本节点(非HTML元素位)
- 您可以找到jsoup text iterator in this answer。 的示例
- 测试文字是否像链接(使用你的正则表达式)
- 替换same example。 中指示的文字
- 获取完整已修改文档的HTML。
- 坐下来享受。
- 标记名称 - 最多255个字符
- 空格 - 最多30个字符
- 属性内容(包括属性和值) - 最多4098个字符
编辑1 - 替换无效HTML的疯狂世界
此问题的作者似乎表示内容不有效的HTML并且需要维护无效的HTML - 因此HTML解析器不应该用作任何HTML解析器可能会在保存时输出有效的HTML。
正如我对原始问题的评论所示,您可以在正则表达式中使用负面外观。但只有傻瓜会用RegEx来解析HTML - 显然我们不是这样的一个可能的例子。
我不会在生产代码中使用它 - 但它会回答OP的问题
RegEx
不幸的是,Java不支持无限制的后视,因此我包含了以下限制:
负面监视
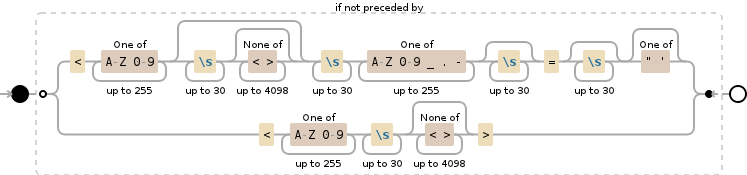 请注意,此可视化不正确,因为
请注意,此可视化不正确,因为[\p{L}0-9_.-]已替换为[A-Z0-9_.-]以使可视化工作正常 - 但\p{L}在技术上更正确,因为“任何Unicode字母”都是可能的。
完整正则表达式
# Negative look-behind
(?<!
## N1: Looks like an HTML attribute value inside a HTML tag
### N1: Tag name
<[A-Z0-9]{1,255}
### N1: Any HTML attributes and values
(?:\s{1,30}[^<>]{0,4098})?
### N1: The begining of a HTML attribute with value
\s{1,30}
[\p{L}0-9_.-]{1,255}
\s{0,30}=\s{0,30}
### N1: Optional HTML attribute quotes
["']?
|
## N2: Looks like the start of an HTML tag text content
### N2: Tag name
<[A-Z0-9]{1,255}\s{1,30}
### N2: All HTML attributes and values
[^<>]{0,4098}
### N2: End of HTML opening tag
>
)
## Positive match: The URL value
((?:https?|ftp|file)://[-a-zA-Z0-9+&@\#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@\#/%=~_|])
Java
import java.util.*;
import java.lang.*;
import java.io.*;
import java.util.regex.*;
class CrazyInvalidHtmlUrlTextFindAndReplacer
{
public static final String EXAMPLE_TEST = "This is a url http://www.google.com <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a><a href=\"http://www.google.com\">http://www.google.com</a><img src=\"http://www.google.com/image.jpg\"><div data-url=\"http://www.google.com\"></div>";
public static final String EXPECTED_OUTPUT_TEST = "This is a url <a href=\"http://www.google.com\">http://www.google.com</a> <a href=\"http://www.google.com\" title=\"Go to Google\">Google</a><a href=\"http://www.google.com\">http://www.google.com</a><img src=\"http://www.google.com/image.jpg\"><div data-url=\"http://www.google.com\"></div>";
public static void main (String[] args) throws java.lang.Exception
{
System.out.println("Starting our non-HTML search and replace...");
StringBuffer resultString = new StringBuffer();
String subjectString = new String(EXAMPLE_TEST);
System.out.println(subjectString);
try {
Pattern regex = Pattern.compile(
"# Negative lookbehind\n" +
"(?<!\n" +
"## N1: Looks like an HTML attribute value inside a HTML tag\n" +
"### N1: Tag name\n" +
"<[A-Z0-9]{1,255}\n" +
"### N1: Any HTML attributes and values\n" +
"(?:\\s{1,30}[^<>]{0,4098})?\n" +
"### N1: The begining of a HTML attribute with value\n" +
"\\s{1,30}\n" +
"[\\p{L}0-9_.-]{1,255}\n" +
"\\s{0,30}=\\s{0,30}\n" +
"### N1: Optional HTML attribute quotes\n" +
"[\"']?\n" +
"|\n" +
"## N2: Looks like the start of an HTML tag text content\n" +
"### N2: Tag name\n" +
"<[A-Z0-9]{1,255}\\s{1,30}\n" +
"### N2: All HTML attributes and values\n" +
"[^<>]{0,4098}\n" +
"### N2: End of HTML opening tag\n" +
">\n" +
")\n" +
"## Positive match: The URL value\n" +
"((?:https?|ftp|file)://[-a-zA-Z0-9+&@\\#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@\\#/%=~_|])",
Pattern.CASE_INSENSITIVE | Pattern.UNICODE_CASE | Pattern.COMMENTS);
Matcher regexMatcher = regex.matcher(subjectString);
while (regexMatcher.find()) {
System.out.println("text");
try {
// You can vary the replacement text for each match on-the-fly
// !!!!!!!!!
// @todo Escape the attribute values and content text.
// !!!!!!!!!
regexMatcher.appendReplacement(resultString, "<a href=\"$1\">$1</a>");
} catch (IllegalStateException ex) {
// appendReplacement() called without a prior successful call to find()
System.out.println("IllegalStateException");
} catch (IllegalArgumentException ex) {
// Syntax error in the replacement text (unescaped $ signs?)
System.out.println("IllegalArgumentException");
} catch (IndexOutOfBoundsException ex) {
// Non-existent backreference used the replacement text
System.out.println("IndexOutOfBoundsException");
}
}
regexMatcher.appendTail(resultString);
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
System.out.println("PatternSyntaxException");
System.out.println(ex.toString());
}
System.out.println("result:");
System.out.println(resultString.toString());
if (resultString.toString().equals(EXPECTED_OUTPUT_TEST)) {
System.out.println("success!!!!");
} else {
System.out.println("failure - expected:");
System.out.println(EXPECTED_OUTPUT_TEST);
}
}
}
不知道在这方面会有什么样的表现 - 后视镜昂贵 - 这一点在RegEx之上通常也很昂贵。
答案 1 :(得分:0)
正如对问题的评论中所讨论的那样,仅使用正则表达式来解决这个问题很难(可能是不可能的?)。下面是一个XSLT样式表,它执行预处理步骤,从输入html中删除所有属性和所有锚标记。
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="node()">
<xsl:copy>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="a">
</xsl:template>
</xsl:stylesheet>
然后你可以运行你的正则表达式来提取剩余的网址,这将更加简单。
如果您的输入html无效,请使用jtidy,htmlcleaner或htmltidy作为进一步的预处理步骤。
希望这有帮助。
答案 2 :(得分:0)
根据Dean和上述例子的建议,这是问题的“解决方案”。请记住,这是一个非常昂贵的,主要是解析HTML字符串(四核/ 16GB RAM MBPr上约160毫秒)。此解决方案还处理有效和无效的HTML。请记住,有一点关于JSOUP的限制,以确保不包含额外的标记,以使最终结果成为有效的HTML。我真的希望有人能提出更好的解决方案,但现在就是这样。
public static String makeHTML(String htmlText){
boolean isValidDoc = false;
if((htmlText.contains("<html") || htmlText.contains("<HTML")) &&
(htmlText.contains("<head") || htmlText.contains("<HEAD")) &&
(htmlText.contains("<body") || htmlText.contains("<BODY"))){
isValidDoc = true;
}
Document doc = Jsoup.parseBodyFragment(htmlText);
final String urlRegex = "\\b(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@#/%=~_|]";
final List<TextNode> nodesToChange = new ArrayList<>();
final List<String> changedContent = new ArrayList<>();
NodeTraversor nd = new NodeTraversor(new NodeVisitor() {
@Override
public void tail(Node node, int depth) {
if (node instanceof TextNode) {
TextNode textNode = (TextNode) node;
Node parent = node.parent();
if(parent.nodeName().equals("a")){
return;
}
String text = textNode.getWholeText();
List<String> allMatches = new ArrayList<String>();
Matcher m = Pattern.compile(urlRegex)
.matcher(text);
while (m.find()) {
allMatches.add(m.group());
}
if(allMatches.size() > 0){
String result = text;
for(String match : allMatches){
result = result.replace(match, "<a href=\"" + match + "\">" + match + "</a>");
}
changedContent.add(result);
nodesToChange.add(textNode);
}
}
}
@Override
public void head(Node node, int depth) {
}
});
nd.traverse(doc.body());
int count = 0;
for (TextNode textNode : nodesToChange) {
String result = changedContent.get(count++);
Node newNode = new DataNode(result, textNode.baseUri());
textNode.replaceWith(newNode);
}
String processed = doc.toString();
if(!isValidDoc){
int start = processed.indexOf("<body>") + 6;
int end = processed.lastIndexOf("</body>");
processed = processed.substring(start, end);
}
return processed;
}
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?