用于解析的正则表达式模式
我需要一个匹配以下各项的模式:
- 除(
:=#\)之外的非空白字符串后跟:,后跟除(:=#\)之外的非空白符号上的一个字符串或 - 一个空格或制表符,后跟一个或多个非空格字符或
- a#后跟任何东西或
- 由一个或多个空格或制表符组成的行或
- 对于以前没有捕获过的东西的收获。
我目前的模式如下:
^([\\S&&[^\\n:=#\\\\]]+):([[\\s&&[^\\n]][\\S&&[^\\n=:#\\\\]]*]*)|^[ \\t](\\S[\\s\\S&&[^\\n]]*)|(^#[\\s\\S&&[^\n]]+)|^([\\s&&[^\\n\\x0B\\f\\r]]+)|([[\\s\\S]&&[^\\n]]+)
我在使用findwithinhorizon(此模式,0)的扫描仪中使用它
在下面的块中,inp是一个缓冲区的扫描程序,_pat是上面的模式。 我遇到了将字符串分配给错误匹配组的问题。
EX:
bob: cat dog
meow
在此扫描程序中运行此命令后,在匹配组2(“cat dog”)上调用.split(\\s+)后,我得到一个空字符串,而第6组(我的错误组)匹配“meow”而不是第3组。
BufferedReader buf =
new BufferedReader(new FileReader(makeFile));
Scanner inp = new Scanner(buf);
while (inp.findWithinHorizon(_pat, 0) != null) {
int i = 1;
MatchResult mat = inp.match();
for (; i <= TOTAL_VALS; i++) {
if (mat.group(i) != null) {
break;
}
}
2 个答案:
答案 0 :(得分:1)
这个正则表达式会将一行分解为适当的组:
([^\s:=#\\]+\s*:\s*(?:[^\s:=#\\]+\s*))|([ \t]\S+)|(#.*)|(\s*)|(.*)
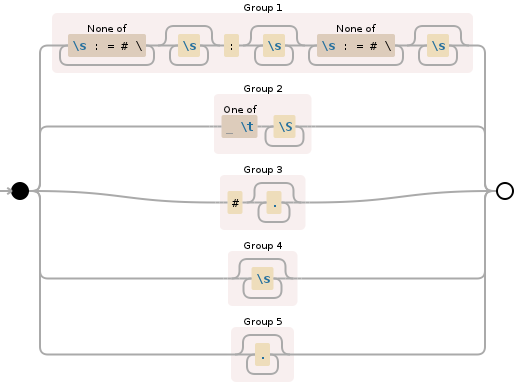
请注意,您的第一个条件实际上与bob: cat dog不匹配。条件应该是这样的:
- 除
:=#\之外的非空白字符串字符串,可选地后跟空格,后跟:可选地后跟空格,后跟另外一个非空格符号字符串,而不是(:=#),用空格分隔OR
样本用法:
String regex = "([^\\s:=#\\\\]+\\s*:\\s*(?:[^\\s:=#\\\\]+\\s*)+)|([ \t]\\S+)|(#.*)|(\\s*)|(.*)";
Pattern p = Pattern.compile(regex);
for (String line : lines) {
Matcher m = p.matcher(line);
m.matches();
for(int i=1;i<m.groupCount();i++) {
System.out.println(i+": "+m.group(i));
}
System.out.println();
}
输入数据:
bob: cat dog
meow
输出将是
1: bob: cat dog
2: null
3: null
4: null
1: null
2: meow
3: null
4: null
答案 1 :(得分:0)
查看正则表达式的一小部分(删除额外的转义)
[\S&&[^\n:=#\\]]+
这在正则表达式语法中没有用。我从你的描述中猜测,模式的这一部分应该是指“一系列不是空格的字符,也不是换行符或:=#\。”这就是你为此编写正则表达式模式的方法:
[^\s:=#\\]+
即。 “一个或多个不是空格的字符,:,=,#或\。
一次一个地接受您的要求:
-
除(
:=#\)之外的非空格字符串后跟:,后跟除(:=#\)之外的非空白符号上的一个字符串或[^\s:=#\\]+:[^\s:=#\\] -
一个空格或制表符,后跟一个或多个非空格字符或
[ \t]\S+ -
a#后跟任何东西OR
#.* -
由一个或多个空格或制表符组成的行。
[ \t]+
把它们放在一起:
^([^\s:=#\\]+:[^\s:=#\\]|[ \t]\S+|#.*|[ \t]+)$
并恢复额外的转义字符,以便将其放入双引号字符串中:
^([^\\s:=#\\\\]+:[^\\s:=#\\\\]|[ \\t]\\S+|#.*|[ \\t]+)$
我遗漏了“catchall”的要求,因为我不清楚为什么它会有用:像something|something else|a third thing|.*这样的正则表达式可以保证匹配任何字符串,并且可能会被{{1为简单起见。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?