使用正则表达式避免使用特殊字符
我正在编写一个Python脚本来从PDF用户pyPdf中提取元数据。
输出是这样的:
{'/Subject': u'Presentation from the 2011 Water Program Peer Review',
'/Producer': u'Mac OS X 10.7.2 Quartz PDFContext',
'/Creator': u'PowerPoint',
'/ModDate': u"D:20120109085812-07'00'",
'/Keywords': u'',
'/Title': u'Wind Wave Float',
'/CreationDate': 'D:20111030043455Z'}
我只需要title和subject字段,因此打印输出最好是:
Wind Wave Float,来自...的演示
因此,我可以轻松地将数据输入电子表格。
任何人都可以帮我一些正则表达式吗?我似乎无法弄清楚如何在输出中使用所有奇怪的字符来完成它。
感谢。
3 个答案:
答案 0 :(得分:2)
您正在查看的输出是字典,因此您想要的信息已经可用。 ' u'您在输出字典中看到的字符串表示该字符串是Unicode格式。
我认为,实现将信息输入电子表格的目标的简单方法是在脚本中添加以下内容:
(在Python 2.x中):
print outputdict['/Title'] + ", " + outputdict['/Subject']
这将为您提供输出:
Wind Wave Float, Presentation from...
(将上面的outputdict替换为提供你已经粘贴在你的问题中的字典输出的任何对象)
答案 1 :(得分:0)
尝试:
(?i)((?<=subject': u')[^']+|(?<=title': u')[^']+)
此正则表达式将匹配来自
的Presentation from the 2011 Water Program Peer Review和Wind Wave Float
{'/Subject': u'Presentation from the 2011 Water Program Peer Review', '/Producer': u'Mac OS X 10.7.2 Quartz PDFContext', '/Creator': u'PowerPoint', '/ModDate': u"D:20120109085812-07'00'", '/Keywords': u'', '/Title': u'Wind Wave Float', '/CreationDate': u'D:20111030043455Z'}
它基本上匹配subject': u'或/Title': u'之后的任何不是'的内容。
答案 2 :(得分:0)
试试这个正则表达式:
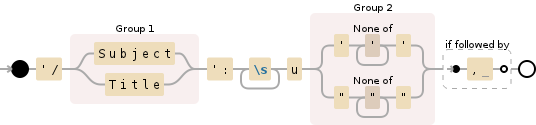
'/(Subject|Title)':\s+u('[^']+'|"[^"]+")(?=, )
描述
演示
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?