需要使用RegEx提取和重新格式化
我正在使用Splunk来解析一些日志,这些日志中嵌入了我们的“hub”和“comp”ID,在邮件正文中。我需要使用字段提取RegEx将它们拉出来:HHHH-CCCC,数据显示如下:
Hub:[HHHH] Comp: [HHHH]
以下是一个示例记录:
RecordID:[00UJ9ANUHO5551212] TrackingID:[1234ANUHO5551212] Hub:[0472] Comp:[N259]发生了一些事件,日志在这里:: [\ server \ share \ 0472 \ N258 \ blah \ blah \ blah \ somefile.txt],没有例外。
由此,我想回来:
0472-N259
我正在努力学习(重新学习!30年前我学会了这些东西!)捕捉群体,并想出了这个:
(?<=Hub:\[)([A-Z0-9]{4})
从中我可以得到4个角色的中心,但它不会让我这样做:
(?<=Hub:\[)([A-Z0-9]{4}) (?<=Comp:\[)([A-Z0-9]{4})
我有点亲近,但是我感到很沮丧,现在是时候回家了,所以我想也许可以帮助我一夜之间。百分之百的最佳答案(请解释解决方案)。我保证在这个问题符合条件时回来奖励。答案不一定是splunk形式(<fieldname>),但这也很有帮助。
如果可以将RegEx粘贴到http://gskinner.com/RegExr/中,那么我可以进一步试验。
6 个答案:
答案 0 :(得分:10)
有两种方法可以实现您的目标...
使用搜索
使用rex提取字段并使用eval连接值。
| rex field=_raw "Hub:\[(?<Hub>[^\]]*)\]\sComp:\[(?<Comp>[^\]]*)\]" | eval someNewField=Hub."-".Comp
rex命令允许您对字段运行正则表达式,_raw是包含整个事件数据的特殊字段名称。正则表达式本身捕获[和]之间的任何字符,并将其提取到<>中指定的字段。
这是最简单的方法,因为您不需要修改任何配置来执行此操作,但缺点是您需要将其添加到搜索字符串中以获取提取的值并按您希望的方式进行格式化。
使用prop.conf和transforms.conf
在transforms.conf中,添加转换以提取字段...
[hubCompExtract]
REGEX = Hub:\[(?<Hub>[^\]]*)\]\sComp:\[(?<Comp>[^\]]*)\]
在props.conf中,执行提取并使用eval ...
[yourSourceTypeName]
REPORT-fieldExtract = hubCompExtract
EVAL-yourNewFieldName = Hub."-".Comp
无需在搜索字符串中添加任何内容,但确实需要更改配置文件。
正则表达式示例
gSkinner example(没有捕获组名称)。
答案 1 :(得分:3)
我不熟悉splunk,但我认为正则表达式支持名为分组。
要创建完全正确的正则表达式,我需要结合一些事情
- 是否始终格式化为
Hub:[HHHH] Comp:[CCCC]?总是Hub,单个空间然后Comp? - ID中总是有4个字符吗?
- 是字母或数字,还是特殊字母
*? - 您如何收到此ID?通过使用某种匹配功能或替换?
这是我的正则表达式:Hub:\s*\[(?<Hub>.{4})\]\s+Comp:\s*\[(?<Comp>.{4})\]
C#中的示例(假设str变量包含一条记录的行)
var regEx = new Regex(@"Hub:\s*\[(?<Hub>.{4})\]\s+Comp:\s*\[(?<Comp>.{4})\]");
var m = regEx.Match(str);
Console.WriteLine(String.Format("{0}-{1}", m.Groups["Hub"], m.Groups["Comp"]));
<强>解释:
如果你想使用Match,你不需要关心你的ID,所以除了ID之外,你不需要在括号中加任何东西。为了便于找到它们,我们使用命名分组(?<someName>pattern)
假设ID总是有4个字符,我们使用{4}。任何字符 - 所以.{4}。
如果您想确保只有字母和数字,可以将其更改为[A-Z0-9]{4}
如果您不知道会有多少个字母/数字,您可以将{4}更改为+ - 这与{1,}相同(从1到无穷大)
发布示例时,在冒号和括号之间放置了额外的空格,因此我放置了:\s*\[
这意味着它可以是:[,: [或任何重复的任何其他空格。
假设Comp在关闭Hub的括号后放置:\]\s+Comp - 它们之间有一个或多个空格。
FYI :如果您计划在开头和结尾.*使用is for replace方法添加,则表示其他任何内容。
var regEx = new Regex(@".*Hub:\s*\[(?<Hub>.{4})\]\s+Comp:\s*\[(?<Comp>.{4})\].*");
Console.WriteLine(regEx.Replace(str, @"${Hub}-${Comp}"));
但是使用replace方法而不是匹配可能会导致不可预测的结果:当字符串与pattern不匹配时,输出字符串与输入相同。因此,在这种情况下(提取某些值时),请始终使用“匹配”方法
答案 2 :(得分:2)
看看这个正则表达式:
(?:Hub|Comp):\[[A-Z0-9]{4}\]
描述
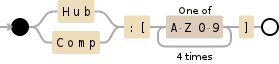
演示
还有更多
您可以匹配整行:^(.*?)(Hub:\[[A-Z0-9]{4}\])(.*?)(Comp:\[[A-Z0-9]{4}\])(.*?)$。
然后用以下代码替换此行:$2-$4。我假设Hub始终在Comp之前。
答案 3 :(得分:2)
你很亲密。尝试抓住你的目标:
Hub:\[([A-Z0-9]{4}) Comp:\[([A-Z0-9]{4})
然后在输出中使用组:
$1-$2
请注意,我不熟悉splunk,因此组的语法可能是反斜杠的变种,即\1-\2
答案 4 :(得分:1)
你可以这样做(如果我理解的话):
pattern: Hub:\[([^\]]+)\] Comp:\[([^\]]+)\]
replacement: $1-$2
[^\]]表示除]
模式可缩短为:Hub:\[([^]]+)\] Comp:\[([^]]+)],带有正则表达式,无需转义方括号。
由于您使用零宽度断言的lookbehinds并且与任何内容都不匹配,因此您的方法不起作用。
答案 5 :(得分:1)
你走了:
Hub:\[([^\]]{4})\] Comp:\[([^\]]{4})\]
为了格式化,请使用反向引用$ 1和$ 2,如下所示:
[$1]-[$2]
这可以假设Comp总是在Hub之后,并且括号之间只有4个条目。
我很想和亚历克斯一样,但这会带来三个问题:
- 无法重新格式化,因为它没有后向引用来仅提取括号内部。
- 无法知道哪个因此无法进行格式化。
- 对每个组件单独进行匹配,将Hub和Comp视为不同的匹配,再次,除非您使用其他形式的处理,否则无法呈现格式。
这是一个很好的方法,只要你可以的话,正则表达式会更好。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?