Ruby:如何在保持分隔符和分隔符的同时拆分字符串的长度> 1?
以前的相关问题只有长度为== 1的分隔符。
我想要的是以下(例如)
str = 'Hello: Alice Hello: Bob Hello: Charlie Hello: David'
arr = str.magic_split('Hello:')
=> arr[0] = 'Hello: Alice '
arr[1] = 'Hello: Bob '
arr[2] = 'Hello: Charlie '
arr[3] = 'Hello: David'
我尝试过str.scan(/ Hello:/),但不知道如何破解正则表达式以使其正常工作。 非常感谢。
我看到一些答案仅适用于这种特殊情况。让我更具体一点。
我要分割的文件如下所示,分隔符为“证书:”
Certificate:
Data: ...
Signature Algorithm: ...
...
-----BEGIN CERTIFICATE-----
F19ibG6uZyBJbmR1c3RyaWVzIEluYzESMBAGA1UECwwJTWV6emFuaW5lMRMwEQYD\n
2O2RV6HR84N2/A5ZPRF8AQMXJCLIR4qMe/d97/1XK6JQQLUI5NaNroUkW3+tjXo/\n
ovl3vom6xOwUUcFDdv2QoCYBVADX7W2RaVP0JGfiDcekOTwtdos/tmsblboR8oEp\n
fbxD45AowT+khXnPDCQWWpslXJoKMBkaWH7ajb+yKfEYGzRPEmq+v/FPMY9mlJhX\n
epciB5FNO5krO+cyhky5tBZTIv7qCu3kc36dcQXIOTakc7CdoVgwLnytebwTqtpG\n
KuLLH46U8Pp3eeiDDBxYJlz6a2bsbtOaKb1CKMFB3x8LLfLbF4Sh+ScDHetkJDh5\n
...
Certificate:
...
Certificate:
...
基本上,在“证书:”之间会有随机的ASCII字符。
再次感谢。
6 个答案:
答案 0 :(得分:5)
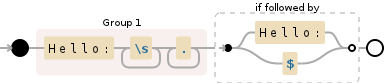
答案 1 :(得分:4)
> str = 'Hello: Alice Hello: Bob Hello: Charlie Hello: David'
=> "Hello: Alice Hello: Bob Hello: Charlie Hello: David"
> str.scan(/Hello: \w+\b/)
=> ["Hello: Alice", "Hello: Bob", "Hello: Charlie", "Hello: David"]
非常依赖于包含字母数字的字符串,但它确实适合您的情况。
答案 2 :(得分:4)
这是使用slice_before:
text = "Certificate:
Data: ...
Signature Algorithm: ...
...
-----BEGIN CERTIFICATE-----
F19ibG6uZyBJbmR1c3RyaWVzIEluYzESMBAGA1UECwwJTWV6emFuaW5lMRMwEQYD
2O2RV6HR84N2/A5ZPRF8AQMXJCLIR4qMe/d97/1XK6JQQLUI5NaNroUkW3+tjXo/
ovl3vom6xOwUUcFDdv2QoCYBVADX7W2RaVP0JGfiDcekOTwtdos/tmsblboR8oEp
fbxD45AowT+khXnPDCQWWpslXJoKMBkaWH7ajb+yKfEYGzRPEmq+v/FPMY9mlJhX
epciB5FNO5krO+cyhky5tBZTIv7qCu3kc36dcQXIOTakc7CdoVgwLnytebwTqtpG
KuLLH46U8Pp3eeiDDBxYJlz6a2bsbtOaKb1CKMFB3x8LLfLbF4Sh+ScDHetkJDh5
...
Certificate:
...
Certificate:
...
"
certificates = text.lines.slice_before(/^Certificate/).to_a
# => [["Certificate:\n",
# " Data: ...\n",
# " Signature Algorithm: ...\n",
# "...\n",
# "-----BEGIN CERTIFICATE-----\n",
# "F19ibG6uZyBJbmR1c3RyaWVzIEluYzESMBAGA1UECwwJTWV6emFuaW5lMRMwEQYD\n",
# "2O2RV6HR84N2/A5ZPRF8AQMXJCLIR4qMe/d97/1XK6JQQLUI5NaNroUkW3+tjXo/\n",
# "ovl3vom6xOwUUcFDdv2QoCYBVADX7W2RaVP0JGfiDcekOTwtdos/tmsblboR8oEp\n",
# "fbxD45AowT+khXnPDCQWWpslXJoKMBkaWH7ajb+yKfEYGzRPEmq+v/FPMY9mlJhX\n",
# "epciB5FNO5krO+cyhky5tBZTIv7qCu3kc36dcQXIOTakc7CdoVgwLnytebwTqtpG\n",
# "KuLLH46U8Pp3eeiDDBxYJlz6a2bsbtOaKb1CKMFB3x8LLfLbF4Sh+ScDHetkJDh5\n",
# "...\n"],
# ["Certificate:\n", "...\n"],
# ["Certificate:\n", "...\n"]]
# ["Certificate:\n", "...\n"]]
slice_before遍历一个数组,寻找与模式匹配的行。当它找到它们时会创建前一行的子数组,然后继续寻找下一个匹配。在上面的输出中,您可以看到为每个创建的证书创建单独的子数组。
这是一种非常有用的方法。
如果在切片之后,您想要获取编码证书,请仅提取这些行,因为它们应设置为偏移量:
certificates.first[5 .. 10]
# => ["F19ibG6uZyBJbmR1c3RyaWVzIEluYzESMBAGA1UECwwJTWV6emFuaW5lMRMwEQYD\n",
# "2O2RV6HR84N2/A5ZPRF8AQMXJCLIR4qMe/d97/1XK6JQQLUI5NaNroUkW3+tjXo/\n",
# "ovl3vom6xOwUUcFDdv2QoCYBVADX7W2RaVP0JGfiDcekOTwtdos/tmsblboR8oEp\n",
# "fbxD45AowT+khXnPDCQWWpslXJoKMBkaWH7ajb+yKfEYGzRPEmq+v/FPMY9mlJhX\n",
# "epciB5FNO5krO+cyhky5tBZTIv7qCu3kc36dcQXIOTakc7CdoVgwLnytebwTqtpG\n",
# "KuLLH46U8Pp3eeiDDBxYJlz6a2bsbtOaKb1CKMFB3x8LLfLbF4Sh+ScDHetkJDh5\n"]
答案 3 :(得分:2)
有很多方法......
str = 'Hello: Alice Hello: Bob Hello: Charlie Hello: David'
str.split("Hello:")[1..-1].map {|s| "Hello:"+s}
或
str.split(/(Hello:)/)[1..-1].each_slice(2).map(&:join)
请注意,在后一种方法中,使用了一个正则表达式,其中包含捕获组中的字符串"Hello:"。结果:
str.split(/(Hello:)/)
#=> ["", "Hello:", " Alice ", "Hello:", " Bob ",
# "Hello:", " Charlie ", "Hello:", " David"]
,而:
str.split(/Hello:/)
#=> ["", " Alice ", " Bob ", " Charlie ", " David"]
答案 4 :(得分:1)
不确定这是否适用于您的特定情况,但您可以尝试:
splitta = "Hello: "
str.split(splitta).drop(1).map { |s| splitta + s }
返回
=> ["Hello: Alice ", "Hello: Bob ", "Hello: Charlie ", "Hello: David"]
答案 5 :(得分:0)
尝试这种模式(Hello:\s*(?:(?:(?!Hello:).)*))
Demo
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?