Java:什么是基于索引的数组访问,为什么它们快?
我继续阅读ArrayList中的搜索速度更快,因为它是基于索引的,与LinkedList等其他数据结构相比。我了解ArrayList内部使用Java array。以下是来自Java ArrayList的代码,该代码将数据保存在array。
private transient Object[] elementData;
什么是'基于索引的数据结构',为什么它更快?
此外,数组的内存模型(数组在堆栈/堆组合中的结构)是什么,以便我能理解为什么访问数组中的元素更快?
3 个答案:
答案 0 :(得分:6)
ArrayList由数组支持。通常,通过索引寻址某事假设为O(1),即,在恒定时间内。在汇编中,您可以在固定时间内索引到内存位置,因为除了基址之外,还有某些LOAD指令采用可选索引。数组通常在内存中分配给一个连续的块。例如,假设您的基地址为0x1000(数组开始的位置),并且您提供的索引为0x08。这意味着,对于从0x1000开始的阵列,您需要访问位置0x1008处的元素。处理器只需要添加基地址和索引,并在内存 * 中查找该位置。这可以在恒定的时间内发生。所以假设你在Java中有以下内容:
int a = myArray[9];
在内部,JVM将知道myArray的地址。与我们的示例一样,我们假设它位于0x1000位置。然后它知道它需要找到9下标。所以基本上它需要找到的位置就是:
0x1000 + 0x09
这给了我们:
0x1009
因此机器可以从那里简单地加载它。
在C中,这实际上更加明显。如果您有一个数组,则可以像Java一样访问i位置myArray[i]。但是您也可以通过指针算法访问它(指针包含指针指向的实际值的地址)!因此,如果您有一个指针*ptrMyArray,则可以通过执行i来访问*(ptrMyArray + i)下标,这与我所描述的完全相同:基地址加下标!
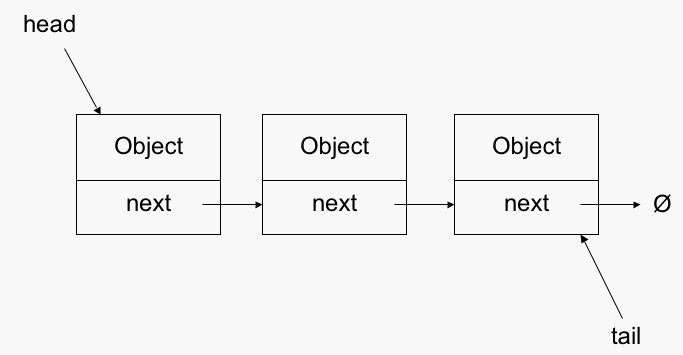
相反,访问LinkedList中某个位置的最糟糕情况是O(n)。如果您回想起数据结构,链表通常有一个head和一个tail指针,每个节点都有一个指向下一个节点的next指针。因此,要查找节点,您必须从head开始,然后依次检查每个节点,直到找到正确的节点。你不能简单地索引到一个位置,因为不能保证链表的节点在内存中彼此相邻;他们可以在任何地方。
* 索引还必须考虑元素的大小,因为您必须考虑每个元素占用的空间大小。我提供的基本示例假定每个元素只占用一个字节。但是如果你有更大的元素,公式基本上是BASE_ADDRESS + (ELEMENT_SIZE_IN_BYTES * INDEX)。在我们的情况下,假设大小为1字节,公式将减少为BASE_ADDRESS + INDEX。
答案 1 :(得分:1)
我不知道JVM的确切内部,这可能因VM而异,但基本上,数组是内存中连续的插槽块。
因此,访问数组[1000]只需要在内存中获取数组的地址,向其中添加1000,并获取存储在此位置的值。
使用链表,您必须获取第一个节点的地址,然后获取此引用引用的对象,然后获取第二个节点的地址等,直到第1000个元素,这使得它慢得多。并且整个事物存储在缓存中的可能性也较小。
答案 2 :(得分:0)

- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?