XslCompiledTransform是否适用于大型文件的慢速XML转换?
我是XSLT的新手,我需要做的第一件事就是解析一个300MB的文件(这就是小端)。 XSLT目前并不复杂,只是删除了一些符合特定条件的节点。 我有两个问题:
- 太慢了。处理500,000条记录需要50秒,而且速度不够快。
- 它消耗500MB的内存,所以只有当文件变大时才会变得更糟。
有什么我可以在.net中本地做的,以使表现更好吗?
我知道我可以研究基于SAX的解析,或STX(在another post中提到),但我更愿意保持在.net边界内。
谢谢!
编辑: 这是我的XSLT
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:test="http://schemas....">
<xsl:output omit-xml-declaration="yes"/>
<xsl:template match="node()|@*">
<xsl:copy>
<xsl:apply-templates select="node()|@*"/>
</xsl:copy>
</xsl:template>
<xsl:template match="test:QueryRow[test:Columns/test:QueryColumn[test:Name='hit_count' and test:Value>200]]"/>
</xsl:stylesheet>
这是我用来进行转换的代码
XslCompiledTransform compiledTransform = new XslCompiledTransform();
XsltSettings settings = new XsltSettings();
settings.EnableScript = true;
XmlReader xmlReader = XmlReader.Create("in.xml");
XmlWriter xmlWriter = XmlWriter.Create("out.xml");
compiledTransform.Load("format.xslt", settings, null);
compiledTransform.Transform(xmlReader, xmlWriter); //this is what takes a long time
目前我正在尝试将文件读入并将其写回,但实际上它似乎是将整个文件读入内存,所以我试图找到一种逐行读取的方法。
3 个答案:
答案 0 :(得分:3)
尝试分析您的XSLT。 oXygen has a nice profiling capability可以告诉您转换中热点的位置。
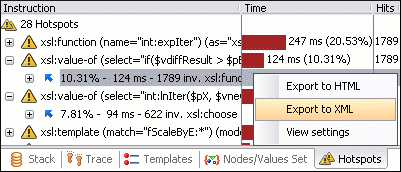
你可能有一些效率低下的XPATH表达式(例如// *),或者在你的模板中埋藏了逻辑(例如,很多for-each,if,choose等),这阻碍了XSLT引擎的优化。将一些逻辑移到模板匹配条件中可以帮助引擎优化并减少迭代和评估的节点集的大小。
答案 1 :(得分:2)
您正在过滤的XPath表达式没有任何明显的错误,因此。但很容易想象它是一个问题。如果您的QueryRow个元素都有20个Column个子元素,每个子元素都有20个QueryColumn子元素,那么XSLT处理器在决定给定的{{1}之前必须检查400个元素。 }元素不匹配。这可能是非常低效的,因为如果事实证明不应该过滤该元素,那么XSLT处理器必须再次访问所有400个元素以将它们全部输出。
实现类似SAX的XML解析的.NET方法是子类QueryRow,在这种情况下你可以想到这样做:你基本上构建了一个缓存XmlReader元素的XmlReader它会读取它们的后代,直到它确定它们没有问题,然后将它们返回给QueryRow方法的调用者。这比使用XSLT过滤XML快得多,因为使用Read不需要在过滤之前构建未过滤的XML文档的内存表示。
答案 2 :(得分:1)
您可以尝试查看Saxon,我听说这是一个非常好用且高效的XSLT处理器。但是完整的XSLT不可能以流方式处理,即使你的转换听起来像是这样,所以除非XSLT处理器非常擅长优化(据我所知,Saxon是最好的,如果不是最好的) ),你的记忆消耗问题可能无法解决。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?