正则表达式从维基百科页面中提取一个部分
我正在尝试解析维基百科页面,需要使用正则表达式提取页面的特定部分。在下面的数据中,我只需要在{{Infobox ...}}部分中提取数据。
{{Infobox XC Championships
|Name = Senior men's race at the 2008 IAAF World Cross Country Championships
|Host city = [[Edinburgh]], [[Scotland]], [[United Kingdom]] {{flagicon|United Kingdom}}
|Location = [[Holyrood Park]]
|Nations participating = 45
}}
2008.<ref name=iaaf_00>
{{ Citation
| last =
| publisher = [[IAAF]]
}}
所以在上面的例子中,我只需要提取
Infobox XC Championships
|Name = Senior men's race at the 2008 IAAF World Cross Country Championships
|Host city = [[Edinburgh]], [[Scotland]], [[United Kingdom]] {{flagicon|United Kingdom}}
|Location = [[Holyrood Park]]
|Nations participating = 45
请注意{{Infobox ...}}部分中可能有嵌套的{{}}个字符。我不想忽略它。
以下是我的正则表达式:
\\{\\{Infobox[^{}]*\\}\\}
但它似乎不起作用。请帮忙。谢谢!
2 个答案:
答案 0 :(得分:4)
由于信息框部分的格式化,实际上可以使用正则表达式。
诀窍是,您甚至不会处理嵌套的{{...}}元素,因为每个元素都将以|开头。
{{(Infobox.*\r\n(?:\|.*\r\n)+)}}
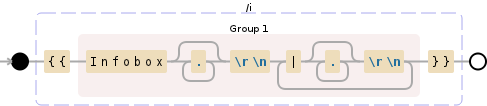
{{ start of the string
(Infobox start of the capturing group
.*\r\n any characters until a line break appears
(?:
\| line has to start with a |
.*\r\n any characters until a line break appears
)
+ the non-capturing group can occur multiple times
) end of capturing group
}}
因此,在Infobox - 部分内,您只需匹配以|开头的行,直到}}弹出。
您可能需要尝试使用\r\n,具体取决于您的平台/语言。 \r\n与\n一样正常,但Debuggex仅匹配{{1}}
答案 1 :(得分:0)
不要使用正则表达式。遵循此算法
1&gt;将counter初始化为0
counter 时, 2&gt;增加{{
3&gt;找到counter
}}
4&gt;重复步骤2和3,直到计数器为0
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?