正则表达式是表的内部HTML,用于查找特殊字符
我很难得到这个......
我有这个HTML代码:
<table border='1'><tr><th></th><th>Fact Questions Report Type Count</th></tr><tr>
<td class=' sorting_1'>0 - 18</td><td>78</td></tr><tr><td class=' sorting_1'>19-64</td>
<td>78</td></tr><tr><td class=' sorting_1'>65+</td><td>78</td></tr><tr>
<td class=' sorting_1'>אין גיל</td><td>78</td></tr><tr><td class=' sorting_1'>נפטר</td>
<td>78</td></tr><tr><td class=' sorting_1'>Unknown</td><td>78</td></tr></table>
如你所见,我想要捕捉的特殊字符如下:
אין גיל,נפטר
我想做一个正则表达式,它会排除所有单词\W和数字\D以及那些 - &gt; =|'
但我无法让它发挥作用..
完美的解决方案是获得两个带有特殊字符的项目...... אין גיל,נפטר
P.S:可能还有其他特殊字符
我很乐意在这里看到一个例子:RegexPal - Online Editor
TNX!
3 个答案:
答案 0 :(得分:2)
如果您试图专门用希伯来语捕捉字符,可以尝试
[\u0590-\u05FF\s]+
假设空格正常,或者,如果使用更高级的正则表达式引擎,
[\p{Hebrew}\s]+
如果你真的试图捕捉非英语但可打印的角色,那么很难在没看到你尝试过的情况下帮助你。 \D是\W的子集,因此您只需要\W+,或者如果我理解正确,您也想排除->=|',那么{{1} (短划线必须在此处(或[^\w>=|-]+之后的第二个位置))。
答案 1 :(得分:1)
这只匹配ASCII printable characters:
[\x20-\x7e]
要捕获那些אין גיל,נפטר(以及许多其他非ASCII字符),您需要
[^\x20-\x7e]
根据要求:regexpal.com
答案 2 :(得分:1)
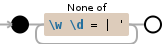
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?