正则表达式Tweek
任何人都可以帮助我更接近我想要获得的结果吗?
我在扫描图像后将此字符串作为OCR结果返回:
7915-03226E3058-089179祝你好运3月4日星期三04你的号码A06 09 26 40 43 45 B 06 14 18 28 43 48 C 02 16 22 34 39 42 1111111 II 111111111111111111111 3次x£1.00表示1平局= E 3.00上周,有超过700,000名获胜者! 7915-032268058-089179 013779期限。 46377201 E - •我填写此框以使票证无效
我试图提取值"A06 09 26 40 43 45","B 06 14 18 28 43 48"和"C 02 16 22 34 39 42"
说实话,我不需要"A","B"和"C"。我只需要每个后面的12个数字。
我有
的正则表达式[A-Z](\W*\d{2}){6}
但是这可以提取我不想要的额外信息,如下所示:http://regexr.com?372b7
有谁能建议如何靠近?有没有更好的方法来尝试获取票号?
3 个答案:
答案 0 :(得分:5)
您的问题主要围绕\W*,这允许任何非单词字符的任何数字(包括0)。因此,基本上111111111111将匹配您的捕获组正则表达式和您的整个正则表达式,如果前面有大写字母。看起来你想要用空格分隔的2位数对,你可以这样做:
[A-Z]\s*(\d{2}\s+){6}

\s+确保至少有一个空白字符分隔对。
虽然上面(与原文一样)只会将最后一对数字放在捕获中。要修复它并忽略尾随空格,可以这样做:
[A-Z]\s*(\d{2}(?:\s+\d{2}){5})

请注意,(?...)正在创建一个非捕获组,因此我们可以在不弄乱捕获组的情况下进行重复操作。现在,这将把所有6对数字放入捕获组1(这将是唯一的额外捕获)。此外,\s*之后的[A-Z]的原因是,似乎在前导字符后面有可选的空格。
答案 1 :(得分:2)
[A-Z]\s*([0-9]{2}\s+){6}
任何大写字母,任意数量的空格(或无),然后是任意2位数后跟一个或多个空格,6次
答案 2 :(得分:2)
试试这个。一个字母,然后是可选空格,然后是六个2位数字,它们之间必须至少有一个空格,但不必在最后有空格
[A-Z]\s*((\d{2}\s+){5}\d{2})
更新
你说你并不特别想要找回A / B / C /字母部分。如果您的正则表达式引擎支持环视,则可以使用:
(?<=[A-Z]\s*)((\d{2}\s+){5}\d{2})
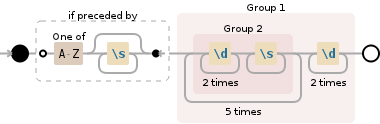
只收到信后的数字。
更新2:更新1可能无效 - 我怀疑重复组可以用于后视。只需使用第一个建议[A-Z]\s*((\d{2}\s+){5}\d{2}),捕获组1将是您所追求的数字。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?