这个备用字符串中的第二个`^`是多余的吗?
在Introducing regular expression的第1章中,我看到了这样的正则表达式:
^(\(\d{3}\)|^\d{3}[.-]?)?\d{3}[.-]?\d{4}$

我有点困惑,因为第二个^看起来多余了。 |在括号内分隔两个备选\(\d{3}\)或^\d{3}[.-]?,括号外有^,我理解为匹配一行的开头,所以我认为^中的第二个^\d{3}[.-]?没有必要匹配行开头。有没有人有这方面的想法?
3 个答案:
答案 0 :(得分:4)
它确实看起来多余,但有一种可能的解释是有效的(尽管在上下文中是非感性的)。
你只在问题中加入了正则表达式模式;你没有告诉我们的是是否使用了任何修饰语。
如果使用m修饰符将正则表达式解析器切换为多行模式,则^和$锚点会更改其含义,以便它们与开头和结尾匹配<强>一行,以及整个字符串。
因此,如果您的表达式使用m修饰符,则额外的^会告诉它在该特定实例中查找额外的换行符。所以它会对表达产生影响。
但最终,看看你所引用的表达方式实际上是什么,我怀疑这是出于预期目的;它看起来好像它基本上是一个错误,正如你所假设的那样。
答案 1 :(得分:1)
是的,它对我来说也是多余的。第一个锚是足够的。
以下是我认为分解为部分的方式:
^
(
\(\d{3}\)
|
^\d{3}[.-]?
)?
\d{3}
[.-]?
\d{4}
$
答案 2 :(得分:1)
是的,那里多余而无用。好吧,它不会崩溃;)
^(\(\d{3}\)|^\d{3}[.-]?)?\d{3}[.-]?\d{4}$
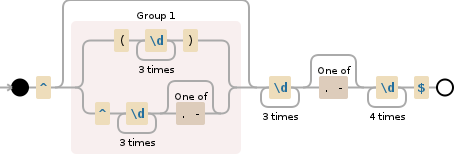
^标记字符串/行开始并且不创建任何结果,并且内部指针也不会移动,因此表达式^,^^或{{1都是平等的。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?