Sql:优化BETWEEN子句
我写了一个声明,花了将近一个小时才能运行所以我正在寻求帮助,所以我可以更快地做到这一点。所以我们走了:
我正在进行两个表的内连接:
我有很多时间间隔用间隔表示,我想从这些间隔内的度量中获取测量数据。
intervals:有两列,一列是开始时间,另一列是间隔的结束时间(行数= 1295)
measures:有两列,一列有度量,另一列有度量时间(行数=一百万)
我想得到的结果是一个表,在第一列中包含度量,然后是度量完成的时间,所考虑的时间间隔的开始/结束时间(对于具有时间的行,将重复该行)考虑范围)
这是我的代码:
select measures.measure as measure, measures.time as time, intervals.entry_time as entry_time, intervals.exit_time as exit_time
from
intervals
inner join
measures
on intervals.entry_time<=measures.time and measures.time <=intervals.exit_time
order by time asc
由于
9 个答案:
答案 0 :(得分:19)
这是一个非常普遍的问题。
普通B-Tree索引不适合这样的查询:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
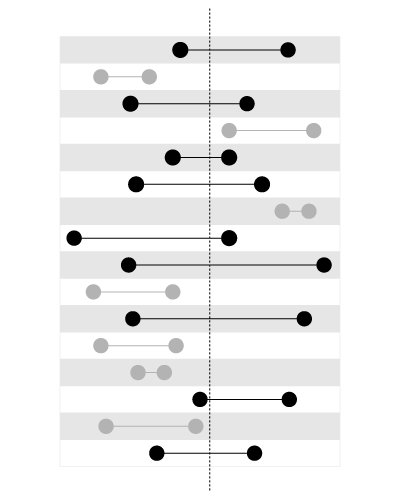
索引适用于搜索给定范围内的值,如下所示:
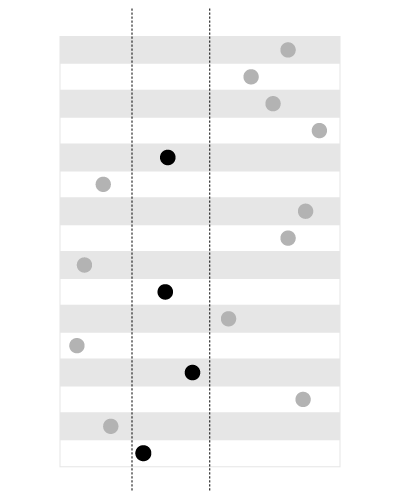
,但不是用于搜索包含给定值的边界,如下所示:
我的博客中的这篇文章更详细地解释了这个问题:
(嵌套集模型处理相似类型的谓词)。
您可以在time上创建索引,这样intervals将在联接中领先,范围时间将在嵌套循环中使用。这需要在time上进行排序。
您可以在intervals上创建空间索引(在MySQL中使用MyISAM存储),在一个几何列中包含start和end。这样,measures可以引导加入,不需要排序。
然而,空间索引更慢,所以只有少量措施但间隔很多时,这才会有效。
由于您的间隔时间很短但有很多措施,因此请确保您在measures.time上有索引:
CREATE INDEX ix_measures_time ON measures (time)
<强>更新
以下是要测试的示例脚本:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
此查询:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
使用NESTED LOOPS并在1.7秒内返回。
此查询:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
使用MERGE JOIN,我必须在5分钟后停止播放。
更新2:
你很可能需要使用这样的提示强制引擎在连接中使用正确的表顺序:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle的优化器不够聪明,看不到间隔不相交。这就是为什么它最有可能使用measures作为主导表(如果间隔相交,这将是一个明智的决定)。
更新3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
此查询将时间轴拆分为范围,并使用HASH JOIN连接范围值的度量和时间戳,稍后进行精细过滤。
在我的博客中查看此文章,了解有关其工作原理的更详细说明:
答案 1 :(得分:3)
答案 2 :(得分:2)
我做的第一件事是让您的数据库工具生成一个可以查看的执行计划(这是MSSQL中的“Control-L”,但我不确定如何在Oracle中执行) - 这将尝试指出缓慢的部分,根据您的服务器/编辑器,它甚至可能会推荐一些基本索引。一旦有了执行计划,就可以查找内部循环连接的任何表扫描,这两者都非常慢 - 索引可以帮助进行表扫描,并且可以添加其他连接谓词来帮助缓解循环连接。
我的猜测是MEASURES需要一个TIME列的索引,你可以包括MEASURE列以加速查找。试试这个:
CREATE INDEX idxMeasures_Time ON Measures ([Time]) INCLUDES (Measure)
此外,虽然这不会改变您的执行计划或加快查询速度,但它可能会使您的连接子句更容易阅读:
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
这只是将您的两个&lt; =和&gt; =组合成一个语句。
答案 3 :(得分:2)
你无法真正优化你的陈述 - 它很简单。
>做的是调查某些指数是否会对您有所帮助。
您选择intervals.entry_time, intervals.exit_time, measures.time - 这些列是否已编入索引?
答案 4 :(得分:2)
尝试并行查询
alter session enable parallel query; select /*+ parallel */ ... same as before;
您也可以使用上面的并行提示创建物化视图。创建MV可能需要很长时间,但一旦创建,就可以重复查询。
答案 5 :(得分:1)
您的SQL等同于:
select m.measure. m.time,
i.entry_time, i.exit_time
from intervals i
join measures m
on m.time Between i.entry_time And i.exit_time
order by time asc
我唯一可能建议的是确保m.Time上有一个索引。然后,如果这不能提高性能,请尝试在i.Start_Time和i.End_Time上添加索引
答案 6 :(得分:1)
如果间隔是确定性的,则可能有一种非常有效的方式来编写此查询,因为查询可以转换为适合更有效散列连接的等连接。
例如,如果间隔全部是每小时:
ENTRY_TIME EXIT_TIME
2000-01-15 09:00:00 2000-01-15 09:59:59
2000-01-15 10:00:00 2000-01-15 10:59:59
2000-01-15 11:00:00 2000-01-15 11:59:59
2000-01-15 12:00:00 2000-01-15 12:59:59
....
然后可以将连接写为:
intervals.entry_time=trunc(measures.time,'HH')
这会降低所有内容的成本,包括连接几乎完全扫描每个表。
但是,由于你在那里有ORDER BY操作,我认为排序合并可能仍然会因为查询现在被写入而击败它,因为优化器将为排序合并排序一个比它更小的数据集。对于散列连接(因为在后一种情况下,它必须排序更多的数据列)。你可以通过将查询结构化为:
来解决这个问题select
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
from
intervals inner join
(select time, measure from measures order by time) measures
on intervals.entry_time=trunc(measures.time,'HH')
/
这比我的10.2.0.4测试实例上的排序合并提供了更低的成本估算,但我认为它有点风险。
所以,我会寻找排序合并或重写它,以便在可能的情况下允许使用散列连接。
答案 7 :(得分:0)
不知道什么是数据库系统和版本,我会说(缺少)索引和join子句可能导致问题。
对于度量表中的每条记录,您可以在区间表(intervals.entry_time<=measures.time)中有多条记录,对于区间表中的每条记录,您可以有多个记录(measures.time <=intervals.exit_time )。由连接引起的一对多和多对一关系意味着每个记录有多个表扫描。我怀疑笛卡尔积是正确的术语,但它非常接近。
索引肯定会有所帮助,但如果你能找到一个更好的密钥加入这两个表,它会更有帮助。将一对多关系向一个方向发展只会加快处理速度,因为不必为每条记录扫描每个表/索引两次。
答案 8 :(得分:0)
在这种情况下,你几乎可以从两个表中获得大部分行,而且你还有一个排序。
问题是,调用进程真的需要所有行,还是只需要前几行?这将改变我如何优化查询。
我假设您的调用进程需要所有行。由于连接谓词不是平等的,我会说MERGE JOIN可能是最好的方法。合并连接需要对其数据源进行排序,因此如果我们可以避免排序,则查询应尽可能快地运行(除非有更多有趣的方法,例如专用索引或物化视图)。
要避免intervals和measures上的SORT操作,您可以在(measures.time,measures.measure)和(intervals.entry_time,{{1}上添加索引}})。数据库可以使用索引来避免排序,并且它会更快,因为它不必访问任何表块。
或者,如果你只在intervals.exit_time上有一个索引,那么查询可能仍然运行正常而不添加另一个大索引 - 它会运行得更慢,因为它可能必须读取许多表块才能获得measures.time用于SELECT子句。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?