еңЁjavascriptдёӯе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ
зӣ®еүҚжҲ‘жӯЈеңЁејҖеҸ‘дёҖдёӘе°Ҷй•ҝеҲ—еҲҶжҲҗзҹӯеҲ—зҡ„еә”з”ЁзЁӢеәҸгҖӮдёәжӯӨжҲ‘е°Ҷж•ҙдёӘж–Үжң¬еҲҶжҲҗеҚ•иҜҚпјҢдҪҶжӯӨеҲ»жҲ‘зҡ„жӯЈеҲҷиЎЁиҫҫејҸд№ҹе°Ҷж•°еӯ—жӢҶеҲҶгҖӮ
жҲ‘еҒҡзҡ„жҳҜиҝҷдёӘпјҡ
str = "This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence.";
sentences = str.replace(/\.+/g,'.|').replace(/\?/g,'?|').replace(/\!/g,'!|').split("|");
з»“жһңжҳҜпјҡ
Array [
"This is a long string with some numbers [125.",
"000,55 and 140.",
"000] and an end.",
" This is another sentence."
]
жңҹжңӣзҡ„з»“жһңжҳҜпјҡ
Array [
"This is a long string with some numbers [125.000, 140.000] and an end.",
"This is another sentence"
]
жҲ‘еҰӮдҪ•жӣҙж”№жҲ‘зҡ„жӯЈеҲҷиЎЁиҫҫејҸжқҘе®һзҺ°иҝҷдёҖзӣ®ж ҮпјҹжҲ‘жҳҜеҗҰйңҖиҰҒжіЁж„ҸеҸҜиғҪйҒҮеҲ°зҡ„дёҖдәӣй—®йўҳпјҹжҲ–иҖ…жҗңзҙў". "пјҢ"? "е’Ң"! "жҳҜеҗҰи¶іеӨҹеҘҪпјҹ
8 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ27)
str.replace(/([.?!])\s*(?=[A-Z])/g, "$1|").split("|")
иҫ“еҮәпјҡ
[ 'This is a long string with some numbers [125.000,55 and 140.000] and an end.',
'This is another sentence.' ]
ж•…йҡңпјҡ
([.?!]) =жҚ•иҺ·.жҲ–?жҲ–!
\s* =еңЁеүҚдёҖдёӘж Үи®°([.?!])еҗҺйқўжҚ•иҺ·0дёӘжҲ–еӨҡдёӘз©әж јеӯ—з¬ҰгҖӮиҝҷдјҡиҖғиҷ‘дёҺиӢұиҜӯиҜӯжі•еҢ№й…Қзҡ„ж ҮзӮ№з¬ҰеҸ·еҗҺйқўзҡ„з©әж јгҖӮ
(?=[A-Z]) =еҰӮжһңдёӢдёҖдёӘеӯ—з¬ҰеңЁA-ZиҢғеӣҙеҶ…пјҲеӨ§еҶҷеӯ—жҜҚAеҲ°еӨ§еҶҷеӯ—жҜҚZпјүпјҢеҲҷеүҚдёҖдёӘж Үи®°еҸӘеҢ№й…ҚгҖӮеӨ§еӨҡж•°иӢұиҜӯиҜӯеҸҘд»ҘеӨ§еҶҷеӯ—жҜҚејҖеӨҙгҖӮд»ҘеүҚзҡ„жӯЈеҲҷиЎЁиҫҫйғҪжІЎжңүиҖғиҷ‘еҲ°иҝҷдёҖзӮ№гҖӮ
жӣҝжҚўж“ҚдҪңдҪҝз”Ёпјҡ
"$1|"
жҲ‘们дҪҝз”ЁдәҶдёҖдёӘвҖңжҚ•иҺ·зҫӨз»„вҖқ([.?!])пјҢжҲ‘们жҚ•иҺ·е…¶дёӯдёҖдёӘеӯ—з¬ҰпјҢ并е°Ҷе…¶жӣҝжҚўдёә$1пјҲеҢ№й…ҚпјүеҠ |гҖӮеӣ жӯӨпјҢеҰӮжһңжҲ‘们жҠ“еҸ–?пјҢйӮЈд№ҲжӣҝжҚўе°Ҷдёә?|гҖӮ
жңҖеҗҺпјҢжҲ‘们жӢҶеҲҶз®ЎйҒ“|并еҫ—еҲ°жҲ‘们зҡ„з»“жһңгҖӮ
жүҖд»ҘпјҢеҹәжң¬дёҠпјҢжҲ‘们жүҖиҜҙзҡ„жҳҜпјҡ
1пјүжүҫеҲ°ж ҮзӮ№з¬ҰеҸ·пјҲ.жҲ–?жҲ–!д№ӢдёҖпјү并жҚ•жҚүе®ғ们
2пјүж ҮзӮ№з¬ҰеҸ·еҸҜд»ҘйҖүжӢ©еҢ…еҗ«з©әж јгҖӮ
3пјүеңЁж ҮзӮ№з¬ҰеҸ·еҗҺпјҢжҲ‘еёҢжңӣжңүдёҖдёӘеӨ§еҶҷеӯ—жҜҚгҖӮ
дёҺд№ӢеүҚжҸҗдҫӣзҡ„жӯЈеҲҷиЎЁиҫҫејҸдёҚеҗҢпјҢиҝҷе°ҶдёҺиӢұиҜӯиҜӯжі•е®Ңе…ЁеҢ№й…ҚгҖӮ
д»ҺйӮЈйҮҢпјҡ
4пјүжҲ‘们йҖҡиҝҮйҷ„еҠ з®ЎйҒ“|
5пјүжҲ‘们жӢҶеҲҶз®ЎйҒ“д»ҘеҲӣе»әдёҖзі»еҲ—еҸҘеӯҗгҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ7)
str.replace(/(\.+|\:|\!|\?)(\"*|\'*|\)*|}*|]*)(\s|\n|\r|\r\n)/gm, "$1$2|").split("|")
RegExpпјҲи§ҒDebuggexпјүпјҡ
- пјҲгҖӮ+ |пјҡ|пјҒ| \пјҹпјү=еҸҘеӯҗдёҚд»…еҸҜд»Ҙд»ҘвҖңгҖӮвҖқпјҢвҖңпјҒвҖқз»“е°ҫгҖӮжҲ–вҖңпјҹвҖқпјҢдҪҶд№ҹеҸҜд»ҘжҳҜвҖң......вҖқжҲ–вҖңпјҡвҖқ
- пјҲ\вҖң | \' |пјү* |} |] пјү=еҸҘеӯҗеҸҜд»Ҙз”ЁеӣӣеҲҶйҹіз¬ҰжҲ–жӢ¬еҸ·жӢ¬иө·жқҘ
- пјҲ\ s | \ n | \ r | \ r \ nпјү=еңЁеҸҘеӯҗеҝ…йЎ»жҳҜз©әж јжҲ–иЎҢе°ҫд№ӢеҗҺ
- g = global
- m = multiline
иҜҙжҳҺпјҡ
- еҰӮжһңдҪҝз”ЁпјҲпјҹ= [A-Z]пјүпјҢRegExpе°Ҷж— жі•еңЁжҹҗдәӣиҜӯиЁҖдёӯжӯЈеёёиҝҗиЎҢгҖӮдҫӢеҰӮгҖӮ вҖңГңвҖқпјҢвҖңДҢвҖқжҲ–вҖңГҒвҖқе°Ҷж— жі•иҜҶеҲ«гҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ6)
жӮЁеҸҜд»ҘеҲ©з”ЁдёӢдёҖеҸҘд»ҘеӨ§еҶҷеӯ—жҜҚжҲ–ж•°еӯ—ејҖеӨҙгҖӮ
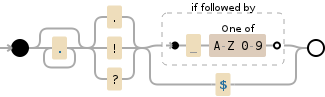
.*?(?:\.|!|\?)(?:(?= [A-Z0-9])|$)
е®ғжӢҶеҲҶжӯӨж–Үжң¬
This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence. Sencenes beginning with numbers work. 10 people like that.
иҝӣе…ҘеҸҘеӯҗпјҡ
This is a long string with some numbers [125.000,55 and 140.000] and an end.
This is another sentence.
Sencenes beginning with numbers work.
10 people like that.
зӯ”жЎҲ 3 :(еҫ—еҲҶпјҡ4)
дҪҝз”ЁеүҚзһ»д»ҘйҒҝе…ҚжӣҝжҚўзӮ№пјҢеҰӮжһңжІЎжңүеҗҺи·ҹз©әж ј+еҚ•иҜҚеӯ—з¬Ұпјҡ
sentences = str.replace(/(?=\s*\w)\./g,'.|').replace(/\?/g,'?|').replace(/\!/g,'!|').split("|");
<ејә>иҫ“еҮәпјҡ
["This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence."]
зӯ”жЎҲ 4 :(еҫ—еҲҶпјҡ4)
дҪҝз”ЁеүҚзһ»жӣҙе®үе…ЁпјҢзЎ®дҝқзӮ№еҗҺйқўзҡ„еҶ…е®№дёҚжҳҜж•°еӯ—гҖӮ
var str ="This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence."
var sentences = str.replace(/\.(?!\d)/g,'.|');
console.log(sentences);
еҰӮжһңдҪ жғіиҰҒжӣҙе®үе…ЁпјҢдҪ еҸҜд»ҘжЈҖжҹҘеҗҺйқўзҡ„ж•°еӯ—жҳҜеҗҰд№ҹжҳҜж•°еӯ—пјҢдҪҶз”ұдәҺJSдёҚж”ҜжҢҒlookbehindпјҢдҪ йңҖиҰҒжҚ•иҺ·еүҚдёҖдёӘеӯ—з¬Ұ并еңЁжӣҝжҚўеӯ—з¬ҰдёІдёӯдҪҝз”Ёе®ғгҖӮ
var str ="This is another sentence.1 is a good number"
var sentences = str.replace(/\.(?!\d)|([^\d])\.(?=\d)/g,'$1.|');
console.log(sentences);
дёҖдёӘжӣҙз®ҖеҚ•зҡ„и§ЈеҶіж–№жЎҲжҳҜйҖғйҒҝж•°еӯ—еҶ…йғЁзҡ„зӮ№пјҲдҫӢеҰӮз”Ё$$$$жӣҝжҚўе®ғ们пјүпјҢиҝӣиЎҢжӢҶеҲҶ然еҗҺеҸ–ж¶ҲзӮ№гҖӮ
зӯ”жЎҲ 5 :(еҫ—еҲҶпјҡ3)
дҪ еҝҳдәҶжҠҠ'\ s'ж”ҫеңЁдҪ зҡ„жӯЈеҲҷиЎЁиҫҫејҸдёӯгҖӮ
е°қиҜ•иҝҷдёӘ
var str = "This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence.";
var sentences = str.replace(/\.\s+/g,'.|').replace(/\?\s/g,'?|').replace(/\!\s/g,'!|').split("|");
console.log(sentences[0]);
console.log(sentences[1]);
зӯ”жЎҲ 6 :(еҫ—еҲҶпјҡ3)
жҲ‘еҸӘжғіжӣҙж”№еӯ—з¬Ұ串并еңЁжҜҸдёӘеҸҘеӯҗд№Ӣй—ҙж·»еҠ дёҖдәӣеҶ…е®№гҖӮ дҪ е‘ҠиҜүжҲ‘дҪ жңүжқғж”№еҸҳе®ғ们пјҢиҝҷж ·еҒҡдјҡжӣҙе®№жҳ“гҖӮ
\r\n
йҖҡиҝҮжү§иЎҢжӯӨж“ҚдҪңпјҢжӮЁжңүдёҖдёӘиҰҒжҗңзҙўзҡ„еӯ—з¬ҰдёІпјҢжӮЁдёҚйңҖиҰҒдҪҝз”ЁиҝҷдәӣеӨҚжқӮзҡ„жӯЈеҲҷиЎЁиҫҫејҸгҖӮ
еҰӮжһңдҪ жғід»Ҙжӣҙйҡҫзҡ„ж–№ејҸдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжқҘеҜ»жүҫпјҶпјғ34;гҖӮпјҶпјғ34; пјҶпјғ34;пјҶпјғ34; пјҶпјғ34;пјҒпјҶпјғ34;д»ҘдёӢжҳҜеӨ§еҶҷеӯ—жҜҚгҖӮе°ұеғҸжі°иҘҝе‘ҠиҜүдҪ зҡ„йӮЈж ·гҖӮ
зӯ”жЎҲ 7 :(еҫ—еҲҶпјҡ0)
@Roger Poonе’Ң@AntonГӯnSlejЕЎkaзҡ„зӯ”жЎҲеҫҲеҘҪгҖӮ
жңҖеҘҪж·»еҠ дҝ®еүӘеҠҹиғҪ并иҝҮж»Өз©әеӯ—з¬ҰдёІпјҡ
const splitBySentence = (str) => {
return str.replace(/([.?!])(\s)*(?=[A-Z])/g, "$1|")
.split("|")
.filter(sentence => !!sentence)
.map(sentence => sentence.trim());
}
const splitBySentence = (str) => {
return str.replace(/([.?!])(\s)*(?=[A-Z])/g, "$1|").split("|").filter(sentence => !!sentence).map(sentence => sentence.trim());
}
const content = `
The Times has identified the following reporting anomalies or methodology changes in the data for New York:
May 6: New York State added many deaths from unspecified days after reconciling data from nursing homes and other care facilities.
June 30: New York City released deaths from earlier periods but did not specify when they were from.
Aug. 6: Our database changed to record deaths by New York City residents instead of deaths that took place in New York City.
Aug. 20: New York City removed four previously reported deaths after reviewing records. The state reported four new deaths in other counties.(extracted from NY Times)
`;
console.log(splitBySentence(content));
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ
- е°Ҷеӯ—з¬ҰдёІжӢҶеҲҶжҲҗеҸҘеӯҗ
- еңЁjavascriptдёӯе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ
- жӯЈеҲҷиЎЁиҫҫејҸе°Ҷеӯ—з¬ҰдёІеҲҶжҲҗеҸҘеӯҗ
- Swiftпјҡе°ҶStringжӢҶеҲҶжҲҗеҸҘеӯҗ
- е°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ - еҝҪз•ҘжӢҶеҲҶзҡ„зј©еҶҷ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ
- еңЁjavascriptдёӯе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеҸҘеӯҗ
- JSе°Ҷж–Үжң¬еҲҶжҲҗеҸҘеӯҗ
- е°ҶеӨҚеҗҲеҸҘеҲҶжҲҗз®ҖеҚ•еҸҘеӯҗ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ