javascript正则表达式在第一个等号分隔字符串
这是我想在文本文件中识别的字符串。文本文件具有我需要在每行中提取的特定字段。例如:
Field1 = This is the content for field 1
Field2 = This is the content for field 2
Field3 = This is the content for field 3, which is = to 4445
假设我想在第一个“=”符号后提取field3的内容。如何获取该内容“这是字段3的内容,即= 4445”,包括第二个“=”符号,但不是第一个。 我正在进入正则表达式,所以我没有多少经验。这是我试过的:
=.*
但这将打印出第一个“=”符号及其后的所有内容。我想省略第一个=符号。
同样,在没有第一个“=”符号的情况下获得“Field3”的正则表达式是什么?我知道我可以根据第一个等号分割线,但我真的需要用regexp来做。谢谢
3 个答案:
答案 0 :(得分:5)
.*?=\s*(.*)
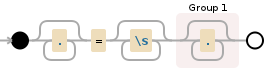
-
.表示除换行符之外的所有字符 -
+意味着另外一个角色 -
()表示捕获组 -
*表示零或更多 -
\s表示空格 -
*?零或多个(懒惰)
将其从捕获组中提取出来。它应该在你的第一个捕获组中。请记住,整个数组存储在匹配的0索引中。
var match = myRegexp.exec(input);
alert(match[1]);
请详细了解regex here并使用debugexx.com进行试验。
答案 1 :(得分:1)
您必须使用捕获组。有点像这样的东西:
str.match(/=\s*(.*)$/)[1];
或者你这样做:
res = str.match(/=\s*(.*)$/);
console.log(res[1]);
如果你想要一个'更安全'的正则表达式,你可以试试这个:
str.match(/^[^=]+=\s*(.*)$/);
^匹配行的开头;
[^=]+匹配除等号以外的任何字符;
=将匹配第一个等号;
(.*)$将捕获第一个等号后的所有内容,直到字符串结束。
答案 2 :(得分:0)
要匹配Field3,您可以使用超前断言:
str.match(/Field3(?=\s*=)/);
如果后跟等号,则匹配Field3,但不会在匹配字符串中包含等号。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?