Python正则表达式提取令牌
我正在尝试查找所有看起来像abc_rty或abc_45或abc09_23k或abc09-K34或4535的令牌。代币不应以_或-或数字开头。
我没有取得任何进展,甚至失去了我所取得的进步。这就是我现在所拥有的:
r'(?<!0-9)[(a-zA-Z)+]_(?=a-zA-Z0-9)|(?<!0-9)[(a-zA-Z)+]-(?=a-zA-Z0-9)\w+'
为了使问题更清楚,这里有一个例子: 如果我有一个字符串如下:
D923-44 43 uou 08*) %%5 89ANB -iopu9 _M89 _97N hi_hello
然后它将接受
D923-44 and 43 and uou and hi_hello
应该忽略
08*) %%5 89ANB -iopu9 _M89 _97N
我可能错过了一些案例,但我认为文本就足够了。道歉,如果不是
2 个答案:
答案 0 :(得分:2)
这似乎符合要求:
regex = re.compile(r"""
(?<!\S) # Assert there is no non-whitespace before the current character
(?: # Start of non-capturing group:
[^\W\d_] # Match either a letter
[\w-]* # followed by any number of the allowed characters
| # or
\d+ # match a string of digits.
) # End of group
(?!\S) # Assert there is no non-whitespace after the current character""",
re.VERBOSE)
在regex101.com上查看。
答案 1 :(得分:2)
^(\d+|[A-Za-z][\w_-]*)$
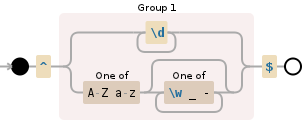
用空格分隔符拆分行,然后通过该行运行此REGEX进行过滤。
-
^是该行的开头 -
\d表示数字[0-9] -
+表示一个或多个 -
|表示OR -
[A-Za-z]第一个字符必须是字母 -
[\w_-]*之后可以有任何字母数字_ +字符或根本没有字符。 -
$表示该行的结尾
REGEX的流程显示在我提供的图表中,这在某种程度上解释了它是如何发生的。
然而,生病解释基本上它检查它是否是所有数字或它以字母(上/下)开头然后在该字母后它检查任何字母数字_ +字符直到行的结尾。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?