在java中使用Regex获取特定的String列表
我的字符串将如下所示,
lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk
lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk
[[test: lls]]
[[test: askd]]
[[test: mmdm]]
[[test: owow]]
[[test: www]]
[[test: wowow]]
我想获取值lls,askd,mmdm等,并将其存储在List中。请注意,这些文本数量巨大。我需要一种有效的方法来解析每个集合并将其存储在List中,而不使用任何外部库。
3 个答案:
答案 0 :(得分:1)
\[\[test:\s([\w]+)\]\]
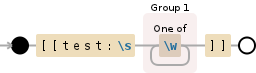
它基本上捕获捕获组中的[[test: *any number and character here* ]],它通常以数组形式返回。
注意:您可能需要转义字符(I.E. \\ [)
答案 1 :(得分:1)
您可以尝试使用正则表达式:
(?<=\[\[test: )[^]]+
另一方面,你需要使用常量java.util.regex.Pattern来避免每次重新编译表达式,如下所示:
private static final Pattern REGEX_PATTERN =
Pattern.compile("(?<=\\[\\[test: )[^]]+");
public static void main(String[] args) {
String input = "lopsakf pkpsdkf pskadp fkpsdkfp sdaf\noksflksflslkf sdlf kasldfk lasdkf lsadfk \nlopsakf pkpsdkf pskadp fkpsdkfp sdaf\noksflksflslkf sdlf kasldfk lasdkf lsadfk lopsakf pkpsdkf pskadp fkpsdkfp sdaf\noksflksflslkf sdlf kasldfk lasdkf lsadfk \n\n[[test: lls]]\n[[test: askd]]\n[[test: mmdm]]\n[[test: owow]]\n[[test: www]]\n[[test: wowow]]";
Matcher matcher = REGEX_PATTERN.matcher(input);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
输出:
lls
askd
mmdm
owow
www
wowow
使用matcher.find()和matcher.group()获取所需的字符串。
另一种方法是,根据可能存在的字符串数量,使用已定义初始容量的java.util.ArrayList实例,以便不需要列表将元素复制到新的内部数组。
答案 2 :(得分:0)
如下所示使用Matcher提取每个字符串并将其添加到列表应该可以正常工作(正则表达式未经测试):
String input = "My input string....";
List<String> myStrings = new ArrayList<String>();
String pattern = "\\[\\[test: (\\w+)\\]\\]";
Matcher matcher = Pattern.compile(pattern).matcher(input);
while (matcher.find())
{
String matchedString = matcher.group(1);
myStrings.add(matchedString);
}
如果您想避免重复的字符串,也可以添加到Set而不是List。
就效率而言,您可以编写一个更有效的解决方案,逐个字符地解析字符串并避免正则表达式开销,但这些收益可能不值得这样做。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?