MySQL正则表达式[a-z] \。[a-z]但不是a.m.或p.m.
晚上,
我想在MySQL表中的某些列中搜索[a-z] \。[a-z]的任何实例,例如:
John.than,Ame.ica,Llan.antffraid等。
但我不希望这包括字符串'a.m.'或者“下午”。我尝试过使用(?!a.m。| p.m。),但这不起作用。它返回错误:“得到错误'重复 - 操作数操作数无效'来自regexp”。
我有以下正则表达式:
REGEXP BINARY '[a-z]\\\.[a-z]'
N.B。如果一个列包括上午或下午。但是还包含像bro.ken这样的字符串,需要返回。
3 个答案:
答案 0 :(得分:3)
逐步构建正则表达式:
你想要一切,除了它是一个“独立的”a.m或p.m:
-
[b-oq-z]{1}\.[a-ln-z]{1}会匹配x.y或a.#或p.#格式
#.m的所有格式
但是你错过了a.a,a.b,a.c ......所以添加这些案例:
-
a\.[^m](同样适用于p- 案例:p\.[^m])
a.m前面有字符时, kra.m, tra.m有效。同样适用于p.m:erp.m
-
[a-z]{1}[ap]\.m涵盖了此条款。
现在,我们缺少字符串,其中第二部分更长:a.mod, p.markt:
-
[ap]\.m[a-z]+涵盖了那个。
最后,只有以.m结尾但具有不同前缀的那些缺失:
-
[b-oq-z]{1}\.m
现在应该涵盖所有可能的用例。简单地将模式与OR(|)结合起来就完成了:
([b-oq-z]{1}\.[a-ln-z]{1}|a\.[^m]|p\.[^m]|[a-z]{1}[ap]\.m|[ap]\.m[a-z]+|[b-oq-z]{1}\.m)
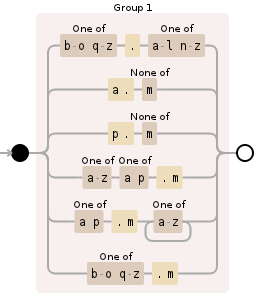
注意:这不会给你exakt匹配组。但是,由于您只在SQL查询中使用它,因此只需要匹配的情况。 (ark.m将与k.m匹配 - 但它符合您的规范)
请记住:创建正则表达式时,没有正确的解决方案:只是工作,而不是工作。 a\.[^m]|p\.[^m]等于[ap]\.[^m],这会将模式减少一个OR。
当满足2个条件时,您已找到完美正则表达式模式:
- 有效!
- 在4个月内查看时,你可以理解它!
答案 1 :(得分:1)
如果你可以使用断言,这可能有用,但不确定回溯。
# (?=^.*(?:(?!a\.m|p\.m)[a-z]\.[a-z]|(?:a\.m|p\.m).*(?!a\.m|p\.m)[a-z]\.[a-z]))
(?=
^
.*
(?:
(?! a\.m | p\.m )
[a-z] \. [a-z]
|
(?: a\.m | p\.m )
.*
(?! a\.m | p\.m )
[a-z] \. [a-z]
)
)
答案 2 :(得分:0)
我会这样做:
SELECT 'Ame.ica wakes up at 8 a.m.' REGEXP
'[b-oq-z]\\.[a-ln-z]|[ap]\\.[^m]|[^ap]\\.m|[[:alpha:]][ap]\\.m|[ap]\\.m[[:alpha:]]' findme,
'America wakes up at 8 a.m.' REGEXP
'[b-oq-z]\\.[a-ln-z]|[ap]\\.[^m]|[^ap]\\.m|[[:alpha:]][ap]\\.m|[ap]\\.m[[:alpha:]]' dontfindme
它是一个更短的,因此更快的版本的dognose的答案。它也是为MySQL量身定制的,它有一些奇怪的[[:alpha:]]类。
相关问题
- 搜索词的正则表达式不在[a-z]和[A-Z]之前或之后
- DateTime.ToString()将meridiem显示为“A.M.”或“P.M.”
- 正则表达式“^ [a-zA-Z]”或“[^ a-zA-Z]”
- ORA-01855:AM / A.M.或PM / P.M。需要
- 正则表达式匹配[^ a-z]或$
- MySQL正则表达式[a-z] \。[a-z]但不是a.m.或p.m.
- Oracle插入时间戳 - AM / A.M.或PM / P.M。需要
- 在MYSQL中选择忽略A.M和P.M的时间
- JOOQ问题:AM / A.M.或PM / P.M。需要
- 如何在Timepicker中选择a.m或p.m时间?
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?