жӯЈеҲҷиЎЁиҫҫејҸ - жҹҘжүҫеҪ©зҘЁеҸ·з Ғ
еҰӮжһңеҸҜиғҪзҡ„иҜқпјҢжҲ‘еёҢжңӣеҫ—еҲ°дёҖдәӣжӯЈи§„зҡ„иЎЁиҫҫжҢҮеҜјпјҢеӣ дёәжҲ‘еҜ№д»–们еҫҲеһғеңҫ:(
жҲ‘е·Із»Ҹжү«жҸҸдәҶеҪ©зҘЁеҲ°ж–Үжң¬пјҢжҲ‘жӯЈеңЁе°қиҜ•д»Һиҝ”еӣһзҡ„ж–Үжң¬дёӯжҠҪеҮәеҪ©зҘЁеҸ·з ҒгҖӮ
иҝҷжҳҜиҝ”еӣһзҡ„еӯ—з¬ҰдёІпјҡ
"if * it вҖў
Including Millionaire Raffle
7618-011874089-204279 111111111111111111111111111111
Goad luck for your draw on Fri 09 Nov 12
Your numbers
Lucky Stars
A 1 8 22 37 47 48 - 03 10
B11 15 26 43 44 - 05 06
C 08 23 27 28 29 - 02 09
D06 09 21 26 29 - 01 05
E 06 07 21 22 45 - 04 05
Your raffle numbers) for your draw(s)
PRC690104
PRC690105
PRC690106
PRC690107
1DRC690108
CHECK YOUR MILLIONAIRE RAFFLE
RESULTS ONLINE AT
WWW.NATIONAL-LOTTERY.CO.UK
5 plays x f2.00 for 1 draw = f10.00
HUGE EUROMILLIONS JACKPOTS TO
PLAY FOR EVERY TUESDAY AND
FRIDAY! PLAY TODAY FOR THE
CHANCE TO WIN YOUR WILDEST
DREAMS!
7618-011874089-204279 035469 Term. 26048301
Fill the box to void the ticket
11111111111111111111111 1111111111111111111111111"
иҝҷжҳҜжү«жҸҸзҡ„еӣҫеғҸпјҡ

жӯЈеҰӮжӮЁжүҖзңӢеҲ°зҡ„пјҢеҪ©зҘЁеҸ·з Ғдјјд№ҺжҖ»жҳҜеҮәзҺ°еңЁвҖңе№ёиҝҗжҳҹвҖқе’ҢвҖңдҪ зҡ„жҠҪеҘ–вҖқд№Ӣй—ҙ
жңүдәәеҸҜд»Ҙе»әи®®еҰӮдҪ•еҲ йҷӨз»“жһңпјҢжүҖд»ҘжҲ‘еҫ—еҲ°вҖңA18223747480310вҖқпјҢвҖңB11152643440506вҖқпјҢвҖңC08232728290209вҖқпјҢвҖңD06092126290105вҖқпјҢвҖңE06072122450405вҖқпјҹ
йқһеёёж„ҹи°ўд»»дҪ•её®еҠ©пјҒ
4 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ1)
Regexе’Ңstring.Splitзҡ„з»„еҗҲдјҡжӣҙз®ҖеҚ•пјҢжӣҙжңүж•Ҳпјҡ
Regex reg = new Regex("(?s)(?<=Lucky Stars).+?(?=Your raffle numbers)");
string[] yourNumbers = Regex.Replace(reg.Match("inputString").Value,"[ -]", "")
.Split(new char[]{'\n'}, StringSplitOptions.RemoveEmptyEntries);
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ1)
и®©жҲ‘们иҜ•зқҖи®©дәӢжғ…еҸҳеҫ—з®ҖеҚ•пјҡжҜҸдёӘеҪ©зҘЁеҸ·з ҒйғҪеҢ…еҗ«дёҖдёӘеӯ—жҜҚAеҲ°EпјҢеҗҺйқўи·ҹзқҖ14дёӘж•°еӯ—пјҢжҜҸдёӘж•°еӯ—еҸҜиғҪжңүеӨҡдёӘз©әж је’Ң/жҲ–иҝһеӯ—з¬ҰпјҲ - пјүд»ӢдәҺдёӨиҖ…д№Ӣй—ҙгҖӮ
жүҖд»ҘиҝҷжҳҜдёҖдёӘжҸҗеҸ–жҜҸдёӘеҪ©зҘЁеҸ·з Ғзҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҡ
[A-E]([\s-]*\d){14}
еҸҜи§ҶеҢ–пјҡпјҲжқҘиҮӘDebuggex demoпјү
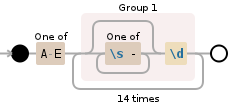
然еҗҺйҖҡиҝҮз”Ёз©әеӯ—з¬ҰдёІжӣҝжҚўжүҖжңүз©әж је’ҢзҹӯеҲ’зәҝжқҘиҺ·еҫ—жүҖйңҖзҡ„з»“жһңгҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
з”ұдәҺз»“жһңеүҚеҜј0пјҲдҫӢеҰӮ08дёә8пјүпјҢеӣ жӯӨз®ҖеҚ•зҡ„ж–№жі•е°ҶжҜҸ2дҪҚж•°еҲҶеүІдёҖж¬ЎгҖӮдёҚйңҖиҰҒжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
зӯ”жЎҲ 3 :(еҫ—еҲҶпјҡ0)
иҝҷеҜ№жӯЈеҲҷиЎЁиҫҫејҸйҖӮз”ЁдәҺжӮЁеҗ‘жҲ‘们еұ•зӨәзҡ„жЎҲдҫӢгҖӮ
/// <summary>
/// Regular expression built for C# on: Sun, Aug 25, 2013, 12:55:52 PM
/// Using Expresso Version: 3.0.4334, http://www.ultrapico.com
///
/// A description of the regular expression:
///
/// Match expression but don't capture it. [Lucky Stars\r\n]
/// Lucky Stars\r\n
/// Lucky
/// Space
/// Stars
/// Carriage return
/// New line
/// [Numbers]: A named capture group. [.*\r\n], exactly 5 repetitions
/// .*\r\n
/// Any character, any number of repetitions
/// Carriage return
/// New line
///
///
/// </summary>
public static Regex regex = new Regex(
"(?:Lucky Stars\\r\\n)(?<Numbers>.*\\r\\n){5}",
RegexOptions.CultureInvariant
| RegexOptions.Compiled
);
public static Regex replaceRegex = new Regex(
"(\\s-.*\r\n)",
RegexOptions.CultureInvariant
| RegexOptions.Compiled
);
ж•°еӯ—жЈҖзҙўзҡ„д»Јз ҒеҰӮдёӢпјҡ
var InputText = @"Lucky Stars
A 1 8 22 37 47 48 - 03 10
B11 15 26 43 44 - 05 06
C 08 23 27 28 29 - 02 09
D06 09 21 26 29 - 01 05
E 06 07 21 22 45 - 04 05
Your raffle numbers";
Match m = regex.Match(InputText);
var numbers = m.Groups["Numbers"].Captures
.OfType<Capture>()
.Select(c => replaceRegex.Replace(c.Value, "").Replace(" ", ""));
дҪҶжҳҜжҲ‘жҖҖз–‘дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҳҜжңҖеҘҪзҡ„и§ЈеҶіж–№жЎҲпјҢд»ҘйҳІдҪ дҪҝз”ЁOCRжҠҖжңҜд»ҺеӣҫзүҮдёӯиҺ·еҸ–ж–Үжң¬гҖӮ
- жӯЈеҲҷиЎЁиҫҫејҸпјҢж•°еӯ—пјҹ
- жӯЈеҲҷиЎЁиҫҫејҸпјҢз”ЁдәҺеңЁHTMLж Үи®°еҶ…жҹҘжүҫж•°еӯ—
- жӯЈеҲҷиЎЁиҫҫејҸ - жҹҘжүҫеҪ©зҘЁеҸ·з Ғ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫйҮҚеӨҚж•°еӯ—
- жӯЈеҲҷиЎЁиҫҫејҸж— жі•жүҫеҲ°ж•°еӯ—еәҸеҲ—
- javascriptжӯЈеҲҷиЎЁиҫҫејҸ - жҹҘжүҫж•°еӯ—е’Ңз©әж ј
- JavascriptеҪ©зҘЁеҸ·з Ғ
- JavaеҪ©зҘЁеҸ·з Ғ
- жӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫз©әж јеҲҶйҡ”зҡ„ж•°еӯ—
- еҪ©зҘЁеҸ·з Ғз”ҹжҲҗеҷЁ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ