用于替换java中字符的多个正则表达式
我有以下字符串:
String str = "Klaße, STRAßE, FUß";
使用组合正则表达式我想分别将德语ß字母替换为 ss 或 SS 。要执行此操作,我有:
String replaceUml = str
.replaceAll("ß", "ss")
.replaceAll("A-Z|ss$", "SS")
.replaceAll("^(?=^A-Z)(?=.*A-Z$)(?=.*ss).*$", "SS");
预期结果:
Klasse, STRASSE, FUSS
实际结果:
Klasse, STRAssE, FUSS
我哪里错了?
4 个答案:
答案 0 :(得分:4)
首先,如果您要尝试匹配A-Z范围内的某些字符,则需要将其放在方括号中。这个
.replaceAll("A-Z|ss$", "SS")
将在源中查找三个字符A-Z,这不是您想要的。其次,我认为你对什么感到困惑手段。如果你这样说:
.replaceAll("[A-Z]|ss$", "SS")
它将用SS替换单词末尾的任何大写字母,因为|意味着寻找这个或。
你的方法的第三个问题是第二个和第三个replaceAll将寻找原始字符串中的任何ss,即使它不是来自ß。这可能是也可能不是你想要的。
这就是我要做的事情:
String replaceUml = str
.replaceAll("(?<=[A-Z])ß", "SS")
.replaceAll("ß", "ss");
如果ß之前的字符是大写字母,则首先用SS替换所有ß;那么如果剩下任何ß,他们会被ss取代。实际上,如果ß之前的角色是像Ä的变音符号,那么这将不起作用,所以你可能应该将其更改为
String replaceUml = str
.replaceAll("(?<=[A-ZÄÖÜ])ß", "SS")
.replaceAll("ß", "ss");
(可能有更好的方法来指定“大写的Unicode字母”;我会寻找它。)
编辑:
String replaceUml = str
.replaceAll("(?<=\\p{Lu})ß", "SS")
.replaceAll("ß", "ss");
问题是,如果ß是文本中的第二个字符,它将无法工作,并且该单词的第一个字母是大写的,但其余单词则不是。在那种情况下,你可能想要小写的“ss”。
String replaceUml = str
.replaceAll("(?<=\\b\\p{Lu})ß(?=\\P{Lu})", "ss")
.replaceAll("(?<=\\p{Lu})ß", "SS")
.replaceAll("ß", "ss");
现在第一个将用ss替换ß,如果它前面是一个大写字母,它是单词的第一个字母,后面是一个不是大写字母的字符。带有大写字母P的\P{Lu}将匹配除大写字母以外的任何字符(\p{Lu}的负数与小写字母p)。我还包括\ b来测试一个单词的第一个字符。
答案 1 :(得分:2)
String replaceUml = str
.replaceAll("(?<=\\p{Lu})ß", "SS")
.replace("ß", "ss")
这使用regex和前面的unicode大写字母(“SÜß”)来获得大写“SS”。
(?<= ... )是一种后视,一种上下文匹配。你也可以这样做
.replaceAll("(\\p{Lu})ß", "$1SS")
因为ß不会在开头出现。
您的主要问题是没有使用括号[A-Z]。
答案 2 :(得分:0)
将正则表达式分解为部分:
Regex 101 Demo
<强>正则表达式
/ß/g
<强> 描述
ß Literal ß
g modifier: global. All matches (don't return on first match)
<强> 可视化
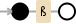
Regex 101 Demo
<强>正则表达式
/([A-Z])ss$/g
<强> 描述
1st Capturing group ([A-Z])
Char class [A-Z] matches:
A-Z A character range between Literal A and Literal Z
ss Literal ss
$ End of string
g modifier: global. All matches (don't return on first match)
<强> 可视化
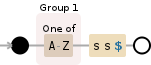
Regex 101 Demo
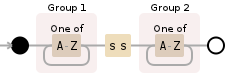
<强>正则表达式
/([A-Z]+)ss([A-Z]+)/g
<强> 描述
1st Capturing group ([A-Z]+)
Char class [A-Z] 1 to infinite times [greedy] matches:
A-Z A character range between Literal A and Literal Z
ss Literal ss
2nd Capturing group ([A-Z]+)
Char class [A-Z] 1 to infinite times [greedy] matches:
A-Z A character range between Literal A and Literal Z
g modifier: global. All matches (don't return on first match)
<强> 可视化
专门为您
String replaceUml = str
.replaceAll("ß", "ss")
.replaceAll("([A-Z])ss$", "$1SS")
.replaceAll("([A-Z]+)ss([A-Z]+)", "$1SS$2");
答案 3 :(得分:-1)
使用 String.replaceFirst()代替String.replaceAll()。
replaceAll("ß", "ss")
这将取代所有出现的“ß”。因此,此语句后的输出变为如下:
Klasse,STRAssE,FUss
现在replaceAll("A-Z|ss$", "SS")用“SS”替换最后一次出现的“ss”,因此你的最终结果如下:
Klasse,STRAssE,FUSS
要获得预期结果,请尝试以下操作:
String replaceUml = str.replaceFirst("ß", "ss").replaceAll("ß", "SS");
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?