快速查找大文本文件中的模式?
我有一个文件,其中有很多空格分隔的文本列。一栏看起来像这样 - 数字是3位或更多位数。例如< 234>,< 9473>等
例如
text.... text... <2329> text...
text.... text... <735> text...
text.... text... <23229> text...
text.... text... <2444> text...
我只想找到这些数字并使用bash打印或保存搜索结果。我该怎么做?
由于
我使用linux [L] ubuntu这样做。
3 个答案:
答案 0 :(得分:3)
这将在your_file中找到包含3位或更多位的所有行,然后输出数字
$ grep -P "<\d{3,}>" your_file | awk -F'[<> ]+' '{print $3}'
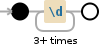
鉴于此文件
text.... text... <1> text...
text.... text... <2329> text...
text.... text... <735> text...
text.... text... <23229> text...
text.... text... <2444> text...
输出
2329
735
23229
2444
答案 1 :(得分:3)
如果列#未修复,您只想捕获<和>之间的数字,请使用:
awk -F '[<>]+' '{for (i=2; i<=NF; i+=2) if ($i ~ /^[0-9][0-9][0-9]+$/) print $i}' file
使用grep -P(perl regex):
grep -oP '(?<=<)\d{3,}(?=>)' file
答案 2 :(得分:1)
由于已经使用了grep和awk,你可以使用sed:)
sed -rn 's/.*<([0-9]{3,})>.*/\1/p' FILE
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?