REGEX要连续获得七个数字?
只是想知道最好的正则表达式是连续七个而且只有七个数字?有没有办法简洁地使用[0-9]七次?或者我应该使用一些????
这七个数字指的是学区ID代码,可以出现在学区维基页面的任何位置。 他们将通过空格与其他内容分开。
输入:这些页面的BeautifulSoup NCES D id位于表格右侧:https://en.wikipedia.org/wiki/Anniston_City_Schools 同样的事情:https://en.wikipedia.org/wiki/Huntsville_City_Schools
Ouptut:一个七位数字,代表区号id:1234567
7 个答案:
答案 0 :(得分:7)
不要使用正则表达式 。使用HTML解析器,例如BeautifulSoup:
from urllib2 import urlopen, Request
from bs4 import BeautifulSoup
resp = urlopen(Request('https://en.wikipedia.org/wiki/Anniston_City_Schools',
headers={'User-Agent': 'Stack Overflow'}))
soup = BeautifulSoup(resp.read())
table = soup.find('table', class_='infobox')
for row in table.find_all('tr'):
if 'NCES' in row.th.text:
nces = row.td.a.text
print nces
break
这会加载URL数据,找到“信息框”表,然后找到带有NCES条目的行。
HTML源代码中有 12 正好7位数字,但上面的代码一次性提取正确的数字。
答案 1 :(得分:5)
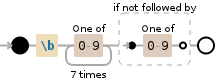
这会查找7个数字,然后确保下一个字符不是另一个数字
\b[0-9]{7}(?![0-9])
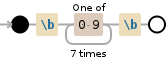
如果您对整个7位数字的匹配空间没问题,这也没关系
\b[0-9]{7}\b
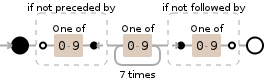
如果你想匹配Asad的例子NCSD Code:1234567这应该有效
(?<![0-9])[0-9]{7}(?![0-9])
答案 2 :(得分:4)
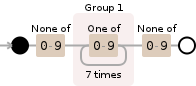
您可以使用:
(?<=^|[^0-9])[0-9]{7}(?=$|[^0-9])
它只匹配7位数字,不多也不少。
或使用负面外观...
(?<![0-9])[0-9]{7}(?![0-9])
答案 3 :(得分:2)
答案 4 :(得分:1)
你可以这样做:
'\s(\d{7})\s'
使用Python re模块:
re.findall('\s(\d{7})\s',s)
测试:
s = 'abc 1 abc 22 abc 333 abcd 666666 ab7777777bc 7777777 abc 88888888'
给出:
#['7777777']
答案 5 :(得分:0)
如果整个字符串可能只是一个七位数字符串,则可以使用以下表达式。它恰好匹配七个数字,并且不允许输入中的任何其他字符(与g1234567或1234567g不匹配):
^(\d{7})$
答案 6 :(得分:0)
最干净的阅读正则表达式是
(?<!\d)\d{7}(?!\d)
但是在Python 3 \d中可以匹配其他书写系统中的数字,因此应该先加(?a)或使用[0-9]而不是\d。
说明:
(?<!\d) # zero-width negative look-behind assertion
# ensures that the following was not preceded by a digit
\d{7} # a digit repeated exactly 7 times
(?!\d) # zero-width negative look-ahead assertion
# ensures that the previously matched 7 digits are not
# followed by an eighth digit.
此处的许多其他答案都是完全错误的,因为它们无法匹配,例如"1234567 blablabla"或"<td>1234567</td>"。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?