我需要一个匹配“origin-xx”的正则表达式
我有一些URI正在进入,我需要捕获子域中具有“origin-xx”的任何URI,并且只能在子域中捕获。我希望返回的匹配等于通配符('xx')。
匹配
-
Origin-www.blahblah.com$match[0] = 'www' -
Origin-uk.blahblah.com$match[0] = 'uk'
不匹配:
-
www.blahblah.com -
www.origin.blahblah.com -
www.blahorigin-blah.com -
uk.blahblah.com
提前致谢。
编辑:我没有说得很清楚。匹配应该只是通配符。因此,如果HTTP_HOST为origin-uk.blahblah.com,则匹配为uk。我编辑了上面的例子以更好地反映这一点。
编辑2:我也应该包括我这样做是PHP。
6 个答案:
答案 0 :(得分:3)
试试这个:
(Origin-(www|uk)(\.(?:[a-zA-Z0-9](?:[_\-][a-zA-Z0-9]*)*)+)+\.com)
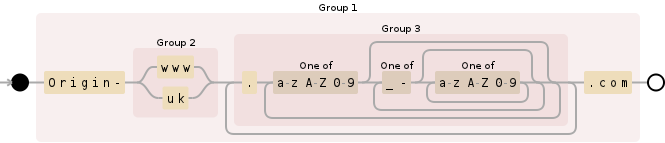
这将捕获您的两个示例,而不会捕获所有“不匹配”的示例。如果您需要更多或更少具体......或不同的东西,您需要澄清。
答案 1 :(得分:2)
哪种风格的正则表达式? 它是用PHP吗?
试试这个:
$pattern = '/^Origin\-([^\.]+)\./';
preg_match($_SERVER['HTTP_HOST'], $pattern, $m);
print $m[1];
答案 2 :(得分:2)
适用于您的一个正则表达式是\b[oO]rigin-(\w+)\b。这是一个RegExr链接:http://regexr.com?35sq3。在此正则表达式中,组1包含您感兴趣的值。 \b字段仅用于删除字符串中间的匹配项。如果您知道Origin位于字符串的开头,则可以将第一个\b替换为^,将最后一个替换为$
答案 3 :(得分:1)
此正则表达式适用于子域:Origin-([a-z]{2}|www)。对于完整的,它可以是:Origin-([a-z]{2}|www)\.blahblah\.com
您可以使用()来引用捕获组。
答案 4 :(得分:1)
在不知道更多参数的情况下,这将起作用 /产地 - ([A-ZA-Z *)\ ./
答案 5 :(得分:1)
首先,你要确保字符串的最开头是“origin”,所以从^开始,这意味着字符串的开头。然后你会匹配任何文字,直到一个点。
/^origin-([a-z]+)\./
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?