正则表达式:未能找到重复模式
我希望能够在一行中捕获重复的组。我完成了我的工作,如下所示;
(((?:\s*^>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*(,\s*[a-zA-Z]+\s*)*;$\s*)|(?:\s*^>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*,\s*[0-9]+\s*(,\s*[\-]?[0-9]+\s*)*;$\s*))+)

它可以单独捕获> 9, 2, door, open;和> 3, 3, door,1, 1;。但是,我也想捕获> 9, 2, door, close; > 1, 9, door, close; > 3, 3, door, 1, 1;。我在最后用括号+量词包围了我的组,但它没有正确地捕获重复模式。你能告诉我我做错了什么吗?
EDITED
我使正则表达式更短,如下所示;
(((\s*>\s*\d+\s*,\s*\d+\s*,\s*\w+\s*(,\s*\w+\s*)*;\s*)|(\s*>\s*\d+\s*,\s*\d+\s*,\s*\w+\s*,\s*\d+\s*(,\s*[\-]?\d+\s*)*;\s*))+)
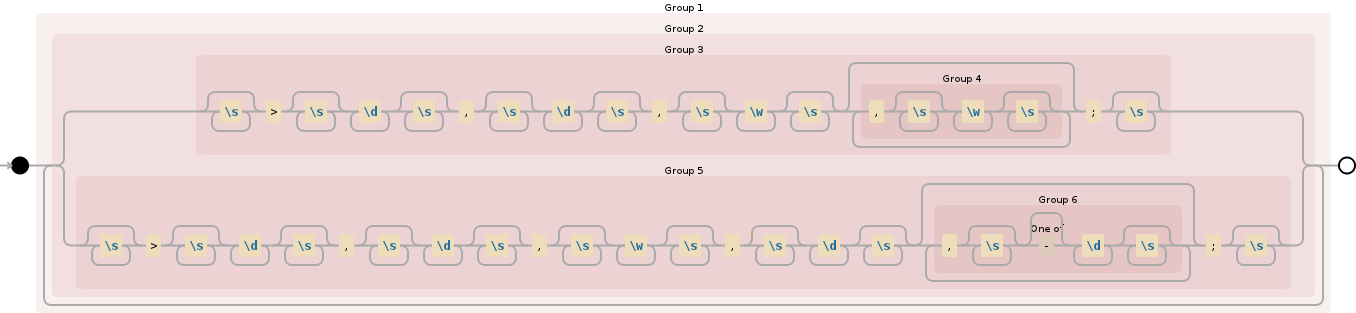
2 个答案:
答案 0 :(得分:2)
如果你想写
> 9, 2, door, close; > 1, 9, door, close; > 3, 3, door, 1, 1;
在一行中,所以你必须完全删除^和$来修复你的正则表达式,这样才能匹配
(((?:\s*>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*(,\s*[a-zA-Z]+\s*)*;\s*)|(?:\s*>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*,\s*[0-9]+\s*(,\s*[\-]?[0-9]+\s*)*;\s*))+)
如果你的意思是
> 9, 2, door, close;
> 1, 9, door, close;
> 3, 3, door, 1, 1;
所以每个人都在一个单独的行中,你需要通过添加多行(/m或(?m))修饰符来修复你的正则表达式,这样就匹配了
(?m)(((?:\s*^>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*(,\s*[a-zA-Z]+\s*)*;$\s*)|(?:\s*^>\s*[0-9]+\s*,\s*[0-9]+\s*,\s*[a-zA-Z]+\s*,\s*[0-9]+\s*(,\s*[\-]?[0-9]+\s*)*;$\s*))+)
希望这能解决您的问题
答案 1 :(得分:0)
我很抱歉,你的正则表达时间太长了以至于我无法阅读...如果你想要的话,你可以为每种格式创建一个不同的格式并包装所有这些,而不是聪明并创建一个小的正则表达式在parens和管道之间。例如,
((\d+)|([a-zA-Z]+))+
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?