正则表达式中的(\ /?)的含义是(\ w +)([^>] *?)冗余?
这个正则表达式应该匹配html开始标记,我想。
var results = html.match(/<(\/?)(\w+)([^>]*?)>/);
我看到它应首先捕获<,但后来我很困惑这个捕获(\/?)完成了什么。我是否正确推理([^>]*?)>搜索除>&gt; = 0次以外的每个字符?如果是这样,为什么(\w+)捕获必要?是否属于[^>]*?
5 个答案:
答案 0 :(得分:4)
通过令牌获取令牌:
-
/开始正则表达式 -
<匹配文字< -
(\/?)匹配0或1(?)文字/,由\转义
-
(\w+)匹配一个或多个“字词” -
([^>]*?)懒惰*匹配任何非*?的零个或多个( -
>匹配文字> -
/end regex literal
>)
懒洋洋地* - 添加“?”在重复之后,量词将使其执行延迟,这意味着正则表达式将匹配前面的标记最少次数。请参阅documentation。
所以基本上这个正则表达式将匹配“&lt;”,可能后跟一个“/”,后跟任意数量的字母,数字或下划线,后跟任何不是“&gt;”的东西,最后跟着通过“&gt;”。
话虽如此,令牌(\w+)并不多余,因为它确保<和>之间至少有一个字符。
请注意attempting to parse HTML with regular expressions is generally a bad idea。
答案 1 :(得分:4)
使用debuggex的强大功能为您生成图像:)
<(\/?)(\w+)([^>]*?)>
将像这样进行评估
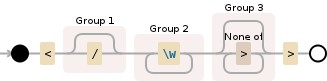
如您所见,它与HTML标记匹配(打开和结束标记)。正则表达式包含三个捕获组,捕获以下内容:
-
(\/?)存在/(这是一个结束标记,如果存在) -
(\w+)代码名称 -
([^>]*?)其他所有内容,直到代码关闭(例如属性)
这样它匹配<a href="#">。有趣的是,它与<a data-fun="fun>nofun">无法正确匹配,因为它停在>属性中的data-fun。虽然(我认为)> is valid in an attribute value。
另一个有趣的事情是,标记名称捕获不会捕获所有理论上有效的XHTML标记。 XHTML允许Letter | Digit | '.' | '-' | '_' | ':' | ..(来源:XHTML spec)。但是,(\w+)与.,-和:不匹配。此正则表达式不匹配虚构的<.foobar>标记。但是,这不应该对现实生活产生任何影响。
你看到使用RgExes解析HTML是一件很危险的事情。使用HTML解析器可能会更好。
答案 2 :(得分:3)
(\/?)匹配并抓取任何结束标记,例如</i>或</strong>如果您熟悉它们?
需要注意的另一件事是\w实际上是字符类[a-zA-Z_\d],因此=,"等其他字符不匹配,但是由[^>]匹配。是的,你对这一点是正确的。
答案 3 :(得分:2)
要回答上一个问题,(\w+)和([^>]*?)并非多余。它们都在表达中起重要作用。
此表达式查找开始或结束标记。
(\/?)与/匹配,但?会将其设为可选。
(\w+)匹配单词字符,用于匹配此处的标记名称。
([^>]*?)旨在匹配属性。
所以如果你有字符串<div class="text">,
表达式中的(\w+)与div匹配,([^>]*?)与class="text"匹配
答案 4 :(得分:0)
演示(在红宝石中,不是javascript,但没有区别):http://www.rubular.com/r/bhw2O28qUr
总结一下,它是捕获结束标记。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?