正则表达式示例混乱
我正在为Oracle Certified Java Programmer做准备。我正在研究正则表达式。我正在浏览javaranch Regular Expression,我无法理解示例中的正则表达式。请帮助我理解它。我在这里添加源代码供参考。感谢。
class Test
{
static Map props = new HashMap();
static
{
props.put("key1", "fox");
props.put("key2", "dog");
}
public static void main(String[] args)
{
String input = "The quick brown ${key1} jumps over the lazy ${key2}.";
Pattern p = Pattern.compile("\\$\\{([^}]+)\\}");
Matcher m = p.matcher(input);
StringBuffer sb = new StringBuffer();
while (m.find())
{
m.appendReplacement(sb, "");
sb.append(props.get(m.group(1)));
}
m.appendTail(sb);
System.out.println(sb.toString());
}
}
4 个答案:
答案 0 :(得分:3)
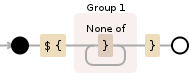
答案 1 :(得分:1)
说明:
\\$ literal $ (must be escaped since it is a special character that
means "end of the string"
\\{ literal { (i m not sure this must be escaped but it doesn't matter)
( open the capture group 1
[^}]+ character class containing all chars but }
) close the capture group 1
\\} literal }
答案 2 :(得分:1)
-
\\$:匹配一个字面的美元符号。没有反斜杠,它匹配字符串的结尾。 -
\\{:匹配文字大括号。 -
(:捕获组的开始-
[^}]:匹配任何不是大括号的字符。 -
+:重复最后一个字符集,它将匹配一个或多个非大括号的字符。
-
-
):关闭捕获组。 -
\\}:匹配文字结束大括号。
它匹配看起来像${key1}的内容。
答案 3 :(得分:1)
Here is a very good tutorial on regular expressions你可能想看看。 The article on quantifiers有两个部分“懒惰而不是贪婪”和“懒惰的替代”,这应该很好地解释这个特定的例子。
无论如何,这是我的解释。首先,您需要意识到Java中有两个编译步骤。将代码中的字符串文字编译为实际字符串。此步骤已经解释了一些反斜杠,因此Java接收的字符串看起来像
\$\{([^}]+)\}
现在让我们在自由间隔模式中选择它:
\$ # match a literal $
\{ # match a literal {
( # start capturing group 1
[^}] # match any single character except } - note the negation by ^
+ # repeat one or more times
) # end of capturing group 1
\} # match a literal }
因此,这确实匹配${...}的所有匹配项,其中...可以是除关闭}之外的任何内容。大括号的内容(即...)稍后可以通过m.group(1)访问,因为它是表达式中的第一组括号。
以下是上述教程的一些更相关的文章(但你应该完整地阅读它 - 它确实值得):
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?