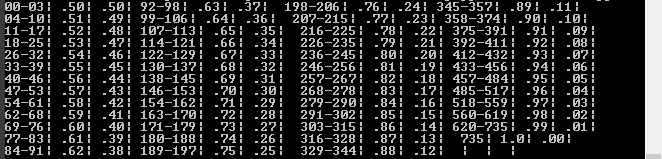
жҲ‘жӯЈеңЁе°қиҜ•дҪҝз”ЁBeautifulSoupжқҘи§ЈжһҗжҲ‘дёҠдј еҲ°http://pastie.org/8070879зҡ„htmlиЎЁпјҢд»Ҙдҫҝе°ҶдёүеҲ—пјҲ0еҲ°735,0.50еҲ°1.0е’Ң0.5еҲ°0.0пјүдҪңдёәеҲ—иЎЁгҖӮдёәдәҶи§ЈйҮҠеҺҹеӣ пјҢжҲ‘еёҢжңӣж•ҙж•°0-735дёәй”®пјҢеҚҒиҝӣеҲ¶ж•°дёәеҖјгҖӮ
йҖҡиҝҮйҳ…иҜ»е…ідәҺSOзҡ„и®ёеӨҡе…¶д»–её–еӯҗпјҢжҲ‘жҸҗеҮәдәҶд»ҘдёӢеҶ…е®№пјҢиҝҷдәӣеҶ…容并жңӘжҺҘиҝ‘еҲӣе»әжҲ‘жғіиҰҒзҡ„еҲ—иЎЁгҖӮе®ғжүҖеҒҡзҡ„еҸӘжҳҜжҳҫзӨәиЎЁж јдёӯзҡ„ж–Үеӯ—пјҢеҰӮhttp://i1285.photobucket.com/albums/a592/TheNexulo/output_zps20c5afb8.png
жүҖзӨәfrom bs4 import BeautifulSoup
soup = BeautifulSoup(open("fide.html"))
table = soup.find('table')
rows = table.findAll('tr')
for tr in rows:
cols = tr.findAll('td')
for td in cols:
text = ''.join(td.find(text=True))
print text + "|",
print
жҲ‘жҳҜPythonе’ҢBeautifulSoupзҡ„ж–°жүӢпјҢжүҖд»ҘиҜ·еҜ№жҲ‘жё©жҹ”пјҒж„ҹи°ў
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ3)
еғҸBeautifulSoupиҝҷж ·зҡ„HTMLи§ЈжһҗеҷЁеҒҮе®ҡдҪ жғіиҰҒзҡ„жҳҜдёҖдёӘеҸҚжҳ иҫ“е…ҘHTMLз»“жһ„зҡ„еҜ№иұЎжЁЎеһӢгҖӮдҪҶжңүж—¶еҖҷпјҲе°ұеғҸеңЁиҝҷз§Қжғ…еҶөдёӢпјүпјҢиҝҷз§ҚжЁЎејҸдёҚд»…д»…жҳҜеё®еҠ©гҖӮ PyparsingеҢ…жӢ¬дёҖдәӣHTMLи§ЈжһҗеҠҹиғҪпјҢиҝҷдәӣеҠҹиғҪжҜ”д»…дҪҝз”ЁеҺҹе§ӢжӯЈеҲҷиЎЁиҫҫејҸжӣҙејәеӨ§пјҢдҪҶжҳҜд»Ҙе…¶д»–зұ»дјјзҡ„ж–№ејҸе·ҘдҪңпјҢи®©жӮЁе®ҡд№үж„ҹе…ҙи¶Јзҡ„HTMLзүҮж®өпјҢиҖҢеҝҪз•Ҙе…¶дҪҷйғЁеҲҶгҖӮиҝҷжҳҜдёҖдёӘи§ЈжһҗжӮЁеҸ‘еёғзҡ„HTMLжәҗд»Јз Ғзҡ„и§ЈжһҗеҷЁпјҡ
from pyparsing import makeHTMLTags,withAttribute,Suppress,Regex,Group
""" looking for this recurring pattern:
<td valign="top" bgcolor="#FFFFCC">00-03</td>
<td valign="top">.50</td>
<td valign="top">.50</td>
and want a dict with keys 0, 1, 2, and 3 all with values (.50,.50)
"""
td,tdend = makeHTMLTags("td")
keytd = td.copy().setParseAction(withAttribute(bgcolor="#FFFFCC"))
td,tdend,keytd = map(Suppress,(td,tdend,keytd))
realnum = Regex(r'1?\.\d+').setParseAction(lambda t:float(t[0]))
integer = Regex(r'\d{1,3}').setParseAction(lambda t:int(t[0]))
DASH = Suppress('-')
# build up an expression matching the HTML bits above
entryExpr = (keytd + integer("start") + DASH + integer("end") + tdend +
Group(2*(td + realnum + tdend))("vals"))
иҝҷдёӘи§ЈжһҗеҷЁдёҚд»…еҸҜд»ҘйҖүеҮәеҢ№й…Қзҡ„дёүе…ғз»„пјҢиҝҳеҸҜд»ҘжҸҗеҸ–иө·е§Ӣж•ҙж•°е’Ңе®һж•°еҜ№пјҲ并且еңЁи§Јжһҗж—¶д№ҹе·Із»Ҹд»Һеӯ—з¬ҰдёІиҪ¬жҚўдёәж•ҙж•°жҲ–жө®зӮ№ж•°пјүгҖӮ
зңӢзқҖжЎҢеӯҗпјҢжҲ‘зҢңдҪ зңҹзҡ„жғіиҰҒдёҖдёӘеғҸ700иҝҷж ·зҡ„еҜҶй’Ҙзҡ„жҹҘжүҫпјҢ然еҗҺиҝ”еӣһиҝҷеҜ№еҖјпјҲ0.99,0.01пјүпјҢеӣ дёә700иҗҪеңЁ620-735зҡ„иҢғеӣҙеҶ…гҖӮиҝҷж®өд»Јз ҒжҗңзҙўжәҗHTMLж–Үжң¬пјҢиҝӯд»ЈеҢ№й…Қзҡ„жқЎзӣ®е№¶е°Ҷй”®еҖјеҜ№жҸ’е…ҘеҲ°dictжҹҘжүҫдёӯпјҡ
# search the input HTML for matches to the entryExpr expression, and build up lookup dict
lookup = {}
for entry in entryExpr.searchString(sourcehtml):
for i in range(entry.start, entry.end+1):
lookup[i] = tuple(entry.vals)
зҺ°еңЁе°қиҜ•дёҖдәӣжҹҘжүҫпјҡ
# print out some test values
for test in (0,20,100,700):
print (test, lookup[test])
жү“еҚ°пјҡ
0 (0.5, 0.5)
20 (0.53, 0.47)
100 (0.64, 0.36)
700 (0.99, 0.01)
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ3)
жҲ‘и®ӨдёәдёҠиҝ°зӯ”жЎҲжҜ”жҲ‘жҸҗдҫӣзҡ„жӣҙеҘҪпјҢдҪҶжҲ‘жңүдёҖдёӘBeautifulSoupзӯ”жЎҲпјҢеҸҜд»Ҙеё®еҠ©дҪ е…Ҙй—ЁгҖӮиҝҷжңүзӮ№hackishпјҢдҪҶжҲ‘жғіжҲ‘дјҡжҸҗдҫӣе®ғгҖӮ
дҪҝз”ЁBeautifulSoupпјҢжӮЁеҸҜд»ҘйҖҡиҝҮд»ҘдёӢж–№ејҸжүҫеҲ°е…·жңүзү№е®ҡеұһжҖ§зҡ„жүҖжңүж Үи®°пјҲеҒҮи®ҫжӮЁе·Із»Ҹи®ҫзҪ®дәҶsoup.objectпјүпјҡ
soup.find_all('td', attrs={'bgcolor':'#FFFFCC'})
иҝҷе°ҶжүҫеҲ°дҪ жүҖжңүзҡ„й’ҘеҢҷгҖӮиҜҖзӘҚжҳҜе°ҶиҝҷдәӣеҖјдёҺжӮЁжғіиҰҒзҡ„еҖјзӣёе…іиҒ”пјҢиҝҷдәӣеҖјйғҪдјҡз«ӢеҚіжҳҫзӨәеҮәжқҘ并且жҲҗеҜ№еҮәзҺ°пјҲеҰӮжһңиҝҷдәӣдәӢжғ…еҸ‘з”ҹеҸҳеҢ–пјҢйЎәдҫҝиҜҙдёҖеҸҘпјҢжӯӨи§ЈеҶіж–№жЎҲе°Ҷж— ж•ҲпјүгҖӮ
еӣ жӯӨпјҢжӮЁеҸҜд»Ҙе°қиҜ•д»ҘдёӢж“ҚдҪңжқҘи®ҝй—®еҜҶй’ҘжқЎзӣ®еҗҺйқўзҡ„еҶ…容并е°Ҷе®ғ们ж”ҫе…Ҙyour_dictionaryпјҡ
for node in soup.find_all('td', attrs={'bgcolor':'#FFFFCC'}):
your_dictionary[node.string] = node.next_sibling
й—®йўҳжҳҜвҖңnext_siblingвҖқе®һйҷ…дёҠжҳҜ'\ n'пјҢжүҖд»ҘдҪ еҝ…йЎ»жү§иЎҢд»ҘдёӢж“ҚдҪңжқҘжҚ•иҺ· next еҖјпјҲдҪ жғіиҰҒзҡ„第дёҖдёӘеҖјпјүпјҡ
for node in soup.find_all('td', attrs={'bgcolor':'#FFFFCC'}):
your_dictionary[node.string] = node.next_sibling.next_sibling.string
еҰӮжһңдҪ жғіиҰҒдёӨдёӘд»ҘдёӢзҡ„еҖјпјҢдҪ еҝ…йЎ»еҠ еҖҚпјҡ
for node in soup.find_all('td', attrs={'bgcolor':'#FFFFCC'}):
your_dictionary[node.string] = [node.next_sibling.next_sibling.string, node.next_sibling.next_sibling.next_sibling.next_sibling.string]
е…ҚиҙЈеЈ°жҳҺпјҡжңҖеҗҺдёҖиЎҢеҜ№жҲ‘жқҘиҜҙйқһеёёйҡҫзңӢгҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
жҲ‘дҪҝз”ЁиҝҮBeautifulSoup 3пјҢдҪҶе®ғеҸҜиғҪдјҡеңЁ4дёӢе·ҘдҪңгҖӮ
# Import System libraries
import re
# Import Custom libraries
from BeautifulSoup import BeautifulSoup
# This may be different between BeautifulSoup 3 and BeautifulSoup 4
with open("fide.html") as file_h:
# Read the file into the BeautifulSoup class
soup = BeautifulSoup(file_h.read())
tr_location = lambda x: x.name == u"tr" # Row location
key_location = lambda x: x.name == u"td" and bool(set([(u"bgcolor", u"#FFFFCC")]) & set(x.attrs)) # Integer key location
td_location = lambda x: x.name == u"td" and not dict(x.attrs).has_key(u"bgcolor") # Float value location
str_key_dict = {}
num_key_dict = {}
for tr in soup.findAll(tr_location): # Loop through all found rows
for key in tr.findAll(key_location): # Loop through all found Integer key tds
key_list = []
key_str = key.text.strip()
for td in key.findNextSiblings(td_location)[:2]: # Loop through the next 2 neighbouring Float values
key_list.append(td.text)
key_list = map(float, key_list) # Convert the text values to floats
# String based dictionary section
str_key_dict[key_str] = key_list
# Number based dictionary section
num_range = map(int, re.split("\s*-\s*", key_str)) # Extract a value range to perform interpolation
if(len(num_range) == 2):
num_key_dict.update([(x, key_list) for x in range(num_range[0], num_range[1] + 1)])
else:
num_key_dict.update([(num_range[0], key_list)])
for x in num_key_dict.items():
print x
{kind=link}