RegEx预测。*
我有一个模式需要找到string1的 last 出现,除非在主题的任何地方找到string2,然后它需要第一次出现string1。为了解决这个问题,我写了这个效率低下的负面预测。
/(.(?!.*?string2))*string1/
运行需要几秒钟(在没有任何字符串出现的主题上过长时间)。有没有更有效的方法来实现这一目标?
5 个答案:
答案 0 :(得分:3)
您应该可以使用以下内容:
/string1(?!.*?string2)/
只要稍后在字符串中找不到string1,我就会匹配string2,我认为这符合您的要求。
修改:看到您的更新后,请尝试以下操作:
/.*?string1(?=.*?string2)|.*string1/
答案 1 :(得分:2)
现在好了,我已经明白了你想要什么,有点长但是优化得很快:
nutria\d. -> string1
RABBIT -> string2
模式(PHP中的示例):
$pattern = <<<LOD
~(?J) # allow multiple capture groups with the same name
### capture the first nutria if RABBIT isn't found before ###
^ (?>[^Rn]++|R++(?!ABBIT)|n++(?!utria\d.))* (?<res>nutria\d.)
### try to capture the last nutria without RABBIT until the end ###
(?>
(?>
(?> [^Rn]++ | R++(?!ABBIT) | n++(?!utria\d.) )*
(?<res>nutria\d.)
)* # repeat as possible to catch the last nutria
(?> [^R]++ | R++(?!ABBIT) )* $ # the end without RABBIT
)? # /!\important/!\ this part is optional, then only the first captured
# nutria is in the result when RABBIT is found in this part
| # OR
### capture the first nutria when RABBIT is found before
^(?> [^n]++ | n++(?!utria\d.) )* (?<res>nutria\d.)
~x
LOD;
$subjects = array( 'groundhog nutria1A beaver nutria1B',
'polecat nutria2A badger RABBIT nutria2B',
'weasel RABBIT nutria3A nutria3B nutria3C',
'vole nutria4A marten nutria4B marmot nutria4C RABBIT');
foreach($subjects as $subject) {
if (preg_match($pattern, $subject, $match))
echo '<br/>'.$match['res'];
}
该模式旨在尽可能快地使用原子组和具有替换的占有量词进行失败,从而避免使用最少可能的前瞻进行灾难性回溯(仅当找到n或R时,它快速失败了)
答案 2 :(得分:2)
您还可以在正则表达式中执行if / else语句!
(?(?=.*string2).*(string1).*$|^.*?(string1))
<强>解释
(? # If
(?=.*string2) # Lookahead, if there is string2
.*(string1).*$ # Then match the last string1
| # Else
^.*?(string1) # Match the first string1
)
如果找到string1,您将在第1组中找到它。
答案 3 :(得分:1)
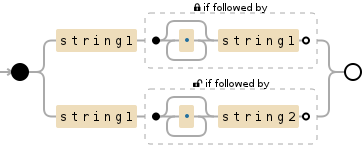
答案 4 :(得分:0)
尝试使用所有格运算符.*+,它使用更少的内存(它不存储匹配情况的整个回溯)。由于这个原因,它也可能运行得更快。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?