使用Python在另一个List中搜索列表的值
我正在尝试查找列表的子列表。意思是如果list1说[1,5]在list2中说[1,4,3,5,6],它应该返回True。到目前为止我所拥有的是:
for nums in l1:
if nums in l2:
return True
else:
return False
这是真的,但是我只是在list1按照相应的顺序在list2中时才尝试返回True。因此,如果list2是[5,2,3,4,1],它应该返回False。我正在考虑使用<来比较list1的索引值。但我不确定。
7 个答案:
答案 0 :(得分:7)
try:
last_found = -1
for num in L1:
last_found = L2.index(num, last_found + 1)
return True
except ValueError:
return False
列表L2的index方法返回列表中第一个参数(num)的位置;像这里一样,用第二个arg调用,它开始查看该位置的列表。如果index找不到它要查找的内容,则会引发ValueError例外。
因此,此代码使用此方法在num内按顺序查找L1的每个项L2。第一次需要从0位开始寻找;每个下一次,它需要从最后一个位置找到前一个项目的位置开始查看,即last_found + 1(所以在开始时我们必须设置last_found = -1以从0位开始查找第一次)。
如果L1中的每个项目都以这种方式找到(即在找到前一项的位置后在L2中找到它),则这两个列表满足给定条件,代码返回True。如果找不到任何L1项,则代码会捕获生成的ValueError异常并返回False。
另一种方法是在两个列表上使用迭代器,这些列表可以使用iter内置函数形成。你可以通过调用内置的next来“推进”迭代器;如果没有“下一个项目”,则会引发StopIteration,即迭代器已用完。您还可以在迭代器上使用for,以获得更平滑的界面(如果适用)。使用iter / next想法的低级方法:
i1 = iter(L1)
i2 = iter(L2)
while True:
try:
lookfor = next(i1)
except StopIteration:
# no more items to look for == all good!
return True
while True:
try:
maybe = next(i2)
except StopIteration:
# item lookfor never matched == nope!
return False
if maybe == lookfor:
break
或更高级别:
i1 = iter(L1)
i2 = iter(L2)
for lookfor in i1:
for maybe in i2:
if maybe == lookfor:
break
else:
# item lookfor never matched == nope!
return False
# no more items to look for == all good!
return True
事实上,iter这里唯一关键的用途是获取i2 - 将内循环设为for maybe in i2,保证内循环不会每次从头开始查看,但是,相反,它将继续寻找它最后停止的地方。外部循环也适用于for lookfor in L1:,因为它没有“重新启动”问题。
Key,这里是循环的else:子句,当且仅当循环没有被break中断而是自然退出时触发。
进一步研究这个想法,我们再次提醒in运算符,它也可以通过使用迭代器继续它最后停止的位置。大简化:
i2 = iter(L2)
for lookfor in L1:
if lookfor not in i2:
return False
# no more items to look for == all good!
return True
但现在我们认识到这正是由短路any和all内置“短路累加器”函数抽象的模式,所以...:
i2 = iter(L2)
return all(lookfor in i2 for lookfor in L1)
我认为这就是你能得到的那么简单。这里留下的唯一非基本位是:您需要显式地使用iter(L2),只需一次,以确保in运算符(本质上是内循环)不会从头重启搜索而是每次从最后一次离开的地方继续。
答案 1 :(得分:2)
这个问题看起来有点像家庭作业,因此我想花时间讨论问题中所示的片段可能出现的问题。
虽然您使用的是复数形式的单词,但对于nums变量,您需要了解Python将使用此变量一次存储来自l1的一个项目,并遍历此代码块中的“for”阻止“,每个不同的项目一次。
因此,当前片段的结果将在第一次迭代时退出,使用True或False,具体取决于列表中的第一项是否恰好匹配。
编辑:是的,A1,正如您所说:在第一次迭代后,逻辑以True退出。这是因为在l2中找到nums时的“返回”
如果你在“找到”的情况下什么都不做,那么逻辑循环将继续完成块中的任何逻辑(这里没有),然后它将开始下一次迭代。因此,在未找到来自l1的项目l2(实际上在第一个这样的未找到项目之后)的情况下,它将仅以“假”返回值退出。因此,你的逻辑几乎是正确的(如果它在“找到的案例”中什么都不做),那么缺少的一件事就是返回“True”,系统地之后for循环(因为如果它没有在循环中以False值退出,那么l2的所有项都在l1 ......)。
有两种方法可以修改代码,因此它对“找到的案例”没有任何作用
- 通过使用传递,这是一种指示Python什么都不做的便捷方式;
“pass”通常用于“某事”,即某些动作在语法上是必需的,但我们不想做任何事情,但也可以在调试等时使用。
- 将测试重写为“不在”而不是
if nums not in l2:
return False
#no else:, i.e. do nothing at all if found
现在......了解更多详情。
您的程序中可能存在缺陷(具有建议的更改),即它将l1视为l2的子列表,即使l1说出2个值为5的项目,其中l2只有一个这样的值。我不确定这种考虑是否是问题的一部分(可能理解是两个列表都是“集合”,没有可能重复的项目)。但是,如果允许重复,则必须稍微复杂化逻辑(可能的方法是在l2副本中找到l2的副本并且每次“nums”,以删除此项目。
另一个考虑因素是,如果列表中的项目与其他列表中的项目的顺序相同,则列表只能说是一个子列表...再次,这一切都取决于问题的定义方式... BTW提出的一些解决方案,比如亚历克斯马尔泰利(Alex Martelli)以这种方式编写,因为他们以一种方式来解决问题,即列表项目的顺序很重要。
答案 2 :(得分:2)
我认为这个解决方案是最快的,因为它只迭代一次,虽然在较长的列表中,如果找到匹配,则在完成迭代之前退出。 (编辑:但是,它不像Alex的最新解决方案那样简洁或快速)
def ck(l1,l2):
i,j = 0,len(l1)
for e in l2:
if e == l1[i]:
i += 1
if i == j:
return True
return False
Anurag Uniyal提出了一项改进(见评论),并反映在下面的摊牌中。
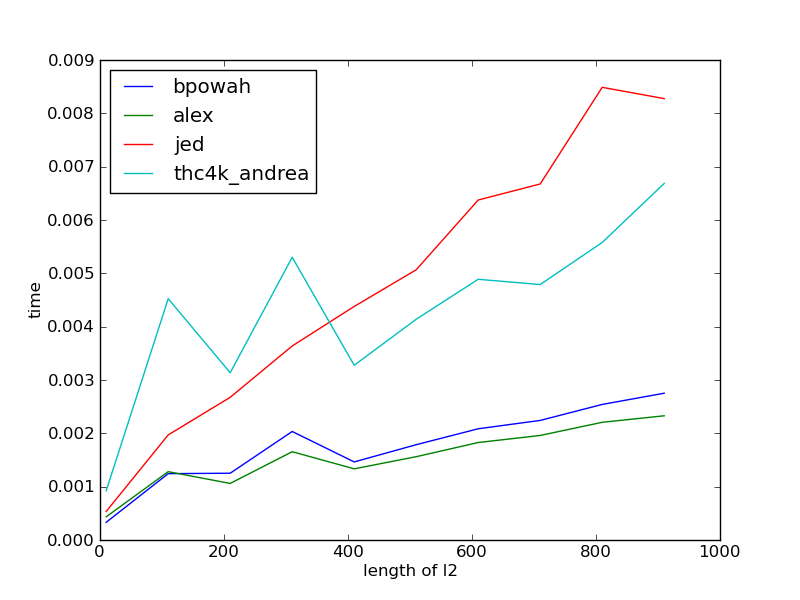
以下是一系列列表大小比率的一些速度结果(列表l1是一个包含1-10的随机值的10个元素列表。列表l2的长度范围为10-1000(并且还包含1-10的随机值。
比较运行时间并绘制结果的代码:
import random
import os
import pylab
import timeit
def paul(l1,l2):
i = 0
j = len(l1)
try:
for e in l2:
if e == l1[i]:
i += 1
except IndexError: # thanks Anurag
return True
return False
def jed(list1, list2):
try:
for num in list1:
list2 = list2[list2.index(num):]
except: return False
else: return True
def alex(L1,L2): # wow!
i2 = iter(L2)
return all(lookfor in i2 for lookfor in L1)
from itertools import dropwhile
from operator import ne
from functools import partial
def thc4k_andrea(l1, l2):
it = iter(l2)
try:
for e in l1:
dropwhile(partial(ne, e), it).next()
return True
except StopIteration:
return False
ct = 100
ss = range(10,1000,100)
nms = 'paul alex jed thc4k_andrea'.split()
ls = dict.fromkeys(nms)
for nm in nms:
ls[nm] = []
setup = 'import test_sublist as x'
for s in ss:
l1 = [random.randint(1,10) for i in range(10)]
l2 = [random.randint(1,10) for i in range(s)]
for nm in nms:
stmt = 'x.'+nm+'(%s,%s)'%(str(l1),str(l2))
t = timeit.Timer(setup=setup, stmt=stmt).timeit(ct)
ls[nm].append( t )
pylab.clf()
for nm in nms:
print len(ss), len(ls[nm])
pylab.plot(ss,ls[nm],label=nm)
pylab.legend(loc=0)
pylab.xlabel('length of l2')
pylab.ylabel('time')
pylab.savefig('cmp_lsts.png')
os.startfile('cmp_lsts.png')
结果:
答案 3 :(得分:1)
这应该很容易理解,并且因为您不需要使用索引,所以可以很好地避免出现问题:
def compare(l1, l2):
it = iter(l2)
for e in l1:
try:
while it.next() != e: pass
except StopIteration: return False
return True
它会尝试将 l1 的每个 e 元素与 l2 中的下一个元素进行比较。
如果没有下一个元素( StopIteration ),它返回false(它访问了整个l2并且没有找到当前的 e ),否则它找到它,所以它返回true
为了更快地执行,将try块放在for:
之外可能会有所帮助def compare(l1, l2):
it = iter(l2)
try:
for e in l1:
while it.next() != e: pass
except StopIteration: return False
return True
答案 4 :(得分:0)
我有一种感觉,这比亚历克斯的答案更加强烈,但这是我的第一个想法:
def test(list1, list2):
try:
for num in list1:
list2 = list2[list2.index(num):]
except: return False
else: return True
编辑:刚尝试过。他的速度更快。它很接近。
编辑2:移动try / except超出循环(这就是其他人应该查看您的代码的原因)。谢谢,gnibbler。
答案 5 :(得分:0)
我很难看到这样的问题,并且不希望Python的列表处理更像是Haskell。这似乎是一个比我在Python中提出的更直接的解决方案:
contains_inorder :: Eq a => [a] -> [a] -> Bool
contains_inorder [] _ = True
contains_inorder _ [] = False
contains_inorder (x:xs) (y:ys) | x == y = contains_inorder xs ys
| otherwise = contains_inorder (x:xs) ys
答案 6 :(得分:0)
Andrea解决方案的超优化版本:
from itertools import dropwhile
from operator import ne
from functools import partial
def compare(l1, l2):
it = iter(l2)
try:
for e in l1:
dropwhile(partial(ne, e), it).next()
return True
except StopIteration:
return False
这可以写成更实用的风格:
def compare(l1,l2):
it = iter(l2)
# any( True for .. ) because any([0]) is False, which we don't want here
return all( any(True for _ in dropwhile(partial(ne, e), it)) for e in l1 )
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?