在MSVC ++中编码源字符集编码,如gcc“-finput-charset = CharSet”
我想创建一些处理编码的示例程序,特别是我想要的 使用宽字符串,如:
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
因为这些是示例程序。
对于将源代码视为UTF-8编码文本的gcc来说,这绝对是微不足道的。 但是,简单的编译在MSVC下不起作用。我知道我可以对它们进行编码 使用转义序列但我更喜欢将它们保留为可读文本。
是否有任何选项可以指定为“cl”的命令行开关
让这个工作吗?
那里有任何命令行开关,如gcc'c -finput-charset
谢谢,
如果不是,你会如何建议让文字对用户自然?
注意:将BOM添加到UTF-8文件不是一个选项,因为它变得不可由其他编译器编译。
注2:我需要它才能在MSVC版本中工作> = 9 == VS 2008
真正的答案:没有解决方案
5 个答案:
答案 0 :(得分:11)
对于那些订阅座右铭"迟到而不是#34;,Visual Studio 2015(编译器的第19版)现在支持这一点。
新的/source-charset命令行开关允许您指定用于解释源文件的字符集编码。它需要一个参数,可以是IANA或ISO字符集名称:
/source-charset:utf-8
或特定代码页的小数标识符(以点开头):
/source-charset:.65001
官方文档为here,Visual C ++团队博客上也有a detailed article describing these new options。
还有一个互补的/execution-charset switch以完全相同的方式工作,但控制在可执行文件中生成的字符和字符串文字的范围。最后,还有一个快捷键/utf-8,用于设置/source-charset:utf-8和/execution-charset:utf-8。
这些命令行选项不兼容与旧的#pragma setlocale和#pragma execution-character-set指令,并且它们全局适用于所有源文件。
对于卡在旧版本编译器上的用户,最好的选择仍然是将源文件保存为带有BOM的UTF-8(正如其他答案所示,IDE可以在保存时执行此操作)。编译器将自动检测到这一点,并且行为恰当。同样,GCC也会在源文件的开头接受BOM而不会窒息死亡,这使得这种方法在功能上可以移植。
答案 1 :(得分:6)
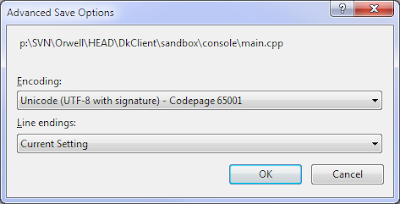
打开File->Advances Save Options...
在编码组合中选择Unicode(UTF-8 with signature) - Codepage 65001。编译器将自动使用选定的编码。
根据微软的回答here:
如果你想要非ASCII字符,那么获得它们的“官方”和可移植方式是使用\ u(或\ U)十六进制编码(我同意,这只是简单的丑陋和容易出错)。 / p>
当编译器面对没有BOM的源文件时,编译器会提前读入文件一定距离,以查看它是否可以检测到任何Unicode字符 - 它专门查找UTF-16和UTF-16BE - 如果它没有找到它然后它假定它有MBCS。我怀疑在这种情况下,它会回到MBCS,这就是导致问题的原因。
明确是最好的,所以虽然我知道它不是一个完美的解决方案我建议使用BOM 。
Jonathan Caves
Visual C ++编译器团队。
好的解决方案是将文本字符串放在资源文件中。它方便又便携。您可以使用本地化库(例如gettext)来管理翻译。
答案 2 :(得分:2)
我们使用的流程:将文件保存为UTF8-BOM,在linux和windows之间共享相同的源,对于linux:在编译命令上预处理源文件以删除BOM,在中间非BOM上运行g ++文件。
答案 3 :(得分:1)
对于VS,您可以使用:
#pragma setlocale( "[locale-string]" )
语言环境的默认ANSI代码页将用作文件编码。
但一般来说,在代码中对任何用户可见的字符串进行硬编码是一个坏主意。 将它们存储在某种资源中。适合本地化,简单的拼写检查和更新等。
答案 4 :(得分:1)
恕我直言,所有C ++源文件都应该是严格的ASCII格式。如果编辑器支持,则注释可以是UTF-8 这使代码可以跨平台,编辑器和源代码控制系统移植。
您可以使用\u将Unicode字符插入宽字符串:
std::wstring str = L"\u20AC123,00"; //€123,00
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?