从网站获取数据
我想创建一个JavaScript代码,可以从其他网站获取这些数据并将其全部放入.TXT文件中,也许即使可以将其转换为XML文件,如果可能的话也会更好。?
如果不是JavaScript,其他任何东西都没问题。
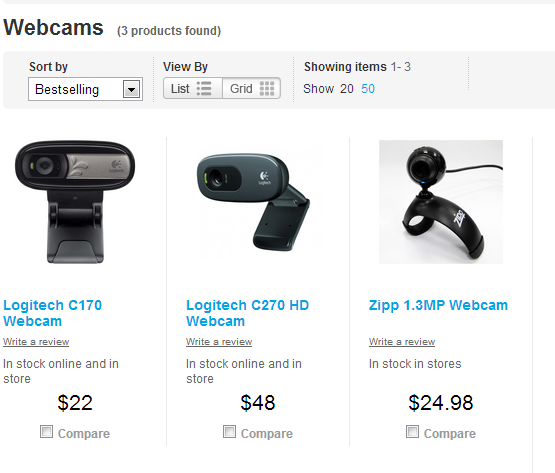
我希望获取价格和商品名称,我不完全确定如何做到这一点。
网站为http://www.bigw.com.au/electronics/computers-office/computer-accessories/webcams,如果您需要阅读其来源以提供帮助。
2 个答案:
答案 0 :(得分:2)
使用浏览器和javascript翻录网站客户端?没问题。
yahoo yql ...(而不是php?代理服务器端脚本)..
我怀疑你不拥有/控制外部链接网站,因此从其他网站获取内容将受到跨域安全限制(对于现代浏览器)。
因此,为了重新获得“用户权力”,只需使用http://query.yahooapis.com/即可。
示例1:
使用类似SQL的命令:
select * from html
where url="http://stackoverflow.com"
and xpath='//div/h3/a'
以下链接将搜索SO以获取最新问题(绕过跨域安全公牛$!!7):
http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20html%20%0Awhere%20url%3D%22http%3A%2F%2Fstackoverflow.com%22%20%0Aand%20xpath%3D'%2F%2Fdiv%2Fh3%2Fa'%3B&format=json&callback=cbfunc
正如您所看到的,这将返回一个JSON数组(也可以选择xml)并调用回调函数:cbfunc。
事实上,作为一个“奖励”,每次你不需要从'tag-soup'中取出正则表达式数据时你也save a kitten,你不需要惹恼lord Cthulu。
你是否听到你内心的小疯狂科学家开始傻笑?
然后查看this answer了解更多信息(不要忘记更多示例的评论)。
获得数据后,您可以随时将其重新发送回服务器,因此重复此操作1000次是没有问题的(只要服务器上有空间)。
祝你好运!
答案 1 :(得分:0)
您可以通过保存页面来获取页面的源代码
或者您可以使用
Right click on webpage ->view source
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?