我试图找出如何使用Python Numpy函数cov计算协方差。当我传递两个一维数组时,我得到了一个2x2的结果矩阵。我不知道该怎么做。我在统计数据上并不擅长,但我认为在这种情况下的协方差应该只是一个数字。我正在寻找This。我自己写了:
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
这很有效,但我认为Numpy版本效率更高,如果我能弄清楚如何使用它。
有人知道如何使Numpy cov功能像我写的那样表现吗?
谢谢,
戴夫
答案 0 :(得分:96)
当a和b是1维序列时,numpy.cov(a,b)[0][1]相当于您的cov(a,b)。
np.cov(a,b)返回的2x2数组的元素等于
cov(a,a) cov(a,b)
cov(a,b) cov(b,b)
(其中,cov是您在上面定义的函数。)
答案 1 :(得分:18)
感谢unutbu的解释。默认情况下,numpy.cov会计算样本协方差。要获得总体协方差,您可以通过总N个样本指定归一化,如下所示:
my %hash = ( key1 => 1 , key2 => 2)
或者像这样:
Covariance = numpy.cov(a, b, bias=True)[0][1]
print(Covariance)
答案 2 :(得分:0)
注意从Python 3.10 release schedule开始,可以直接从标准库中获取协方差。
使用 statistics.covariance 这是两个输入的联合可变性的度量(您正在寻找的数字):
from statistics import covariance
# x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# y = [1, 2, 3, 1, 2, 3, 1, 2, 3]
covariance(x, y)
# 0.75
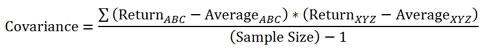{kind=link}